
视图文件系统 (ViewFs) 提供了一种管理多个 Hadoop 文件系统命名空间(或命名空间卷)的方法。它对于具有多个名称节点(因此具有多个命名空间)的群集特别有用,在 HDFS 联合 中。ViewFs 类似于某些 Unix/Linux 系统中的客户端挂载表。ViewFs 可用于创建个性化命名空间视图以及每个群集的公共视图。
本指南是在具有多个群集的 Hadoop 系统的上下文中介绍的,每个群集都可以联合到多个命名空间中。它还描述了如何在联合 HDFS 中使用 ViewFs 来提供每个群集的全局命名空间,以便应用程序可以以类似于联合之前的方式进行操作。
在 HDFS 联合 之前的旧世界中,一个群集有一个名称节点,该名称节点为该群集提供了一个文件系统命名空间。假设有多个群集。每个群集的文件系统命名空间是完全独立且不相交的。此外,物理存储不会在群集之间共享(即数据节点不会在群集之间共享)。
每个群集的 core-site.xml 都具有一个配置属性,该属性将默认文件系统设置为该群集的名称节点
<property> <name>fs.default.name</name> <value>hdfs://namenodeOfClusterX:port</value> </property>
这样的配置属性允许人们使用相对斜杠的名称来解析相对于群集名称节点的路径。例如,路径 /foo/bar 正在使用上述配置引用 hdfs://namenodeOfClusterX:port/foo/bar。
此配置属性设置在群集上的每个网关上,也设置在该群集的关键服务(如 JobTracker 和 Oozie)上。
因此,在 core-site.xml 设置为上述内容的群集 X 上,典型的路径名为
/foo/bar
hdfs://namenodeOfClusterX:port/foo/bar。hdfs://namenodeOfClusterX:port/foo/bar
/foo/bar,因为它允许在需要时将应用程序及其数据透明地移动到另一个群集。hdfs://namenodeOfClusterY:port/foo/bar
distcp hdfs://namenodeClusterY:port/pathSrc hdfs://namenodeClusterZ:port/pathDest
webhdfs://namenodeClusterX:http_port/foo/bar
http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和 http://proxyClusterX:http_port/foo/bar
当在集群中时,建议使用类型 (1) 的路径名,而不是像 (2) 这样的完全限定的 URI。完全限定的 URI 类似于地址,不允许应用程序随其数据一起移动。
假设有多个集群。每个集群有一个或多个 namenode。每个 namenode 都有自己的命名空间。一个 namenode 属于一个且仅属于一个集群。同一集群中的 namenode 共享该集群的物理存储。跨集群的命名空间与以前一样独立。
操作根据存储需求决定在集群中的每个 namenode 上存储什么。例如,它们可能会将所有用户数据 (/user/<username>) 放在一个 namenode 中,将所有 feed 数据 (/data) 放在另一个 namenode 中,将所有项目 (/projects) 放在另一个 namenode 中,依此类推。
为了提供与旧世界的透明性,ViewFs 文件系统(即客户端挂载表)用于为每个集群创建一个独立的集群命名空间视图,类似于旧世界的命名空间。客户端挂载表类似于 Unix 挂载表,它们使用旧的命名约定挂载新的命名空间卷。下图显示了一个挂载表,挂载了四个命名空间卷 /user、/data、/projects 和 /tmp
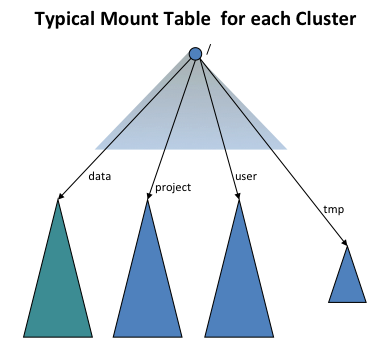
ViewFs 实现 Hadoop 文件系统接口,就像 HDFS 和本地文件系统一样。从某种意义上说,它是一个简单的文件系统,因为它只允许链接到其他文件系统。由于 ViewFs 实现 Hadoop 文件系统接口,因此它可以透明地使用 Hadoop 工具。例如,所有 shell 命令都可以与 ViewFs 一起使用,就像与 HDFS 和本地文件系统一起使用一样。
在每个集群的配置中,默认文件系统设置为该集群的挂载表,如下所示(将其与单名称节点集群中的配置进行比较)。
<property> <name>fs.defaultFS</name> <value>viewfs://clusterX</value> </property>
URI 中viewfs://方案后面的权限是挂载表名称。建议将集群的挂载表命名为集群名称。然后,Hadoop 系统将在 Hadoop 配置文件中查找名称为“clusterX”的挂载表。操作安排所有网关和服务机器以包含所有集群的挂载表,以便为每个集群,默认文件系统设置为该集群的 ViewFs 挂载表,如上所述。
挂载表的挂载点在标准 Hadoop 配置文件中指定。viewfs的所有挂载表配置条目都以fs.viewfs.mounttable.为前缀。使用link标签指定链接其他文件系统的挂载点。建议将挂载点名称与链接的文件系统目标位置中的名称相同。对于挂载表中未配置的所有命名空间,我们可以通过linkFallback将其回退到默认文件系统。
在下面的挂载表配置中,命名空间/data链接到文件系统hdfs://nn1-clusterx.example.com:8020/data,/project链接到文件系统hdfs://nn2-clusterx.example.com:8020/project。挂载表中未配置的所有命名空间(如/logs)都链接到文件系统hdfs://nn5-clusterx.example.com:8020/home。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://nn1-clusterx.example.com:8020/data</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./project</name>
<value>hdfs://nn2-clusterx.example.com:8020/project</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://nn3-clusterx.example.com:8020/user</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn4-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://nn5-clusterx.example.com:8020/home</value>
</property>
</configuration>
或者,我们可以通过linkMergeSlash将挂载表的根与另一个文件系统的根合并。在下面的挂载表配置中,集群 Y 的根与hdfs://nn1-clustery.example.com:8020处的根文件系统合并。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterY.linkMergeSlash</name>
<value>hdfs://nn1-clustery.example.com:8020/</value>
</property>
</configuration>
因此,在集群 X 上,其中core-site.xml设置为使默认 fs 使用该集群的挂载表,典型的路径名为
/foo/bar
viewfs://clusterX/foo/bar。如果在旧的非联合世界中使用了此类路径名,那么向联合世界的过渡是透明的。viewfs://clusterX/foo/bar
/foo/bar,因为它允许在需要时将应用程序及其数据透明地移动到另一个集群。viewfs://clusterY/foo/bar
distcp viewfs://clusterY/pathSrc viewfs://clusterZ/pathDest
viewfs://clusterX-webhdfs/foo/bar
http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和 http://proxyClusterX:http_port/foo/bar
当在集群中时,建议使用类型 (1) 的路径名,而不是像 (2) 这样的完全限定 URI。此外,应用程序不应使用装载点的知识,也不应使用类似 hdfs://namenodeContainingUserDirs:port/joe/foo/bar 的路径来引用特定名称节点中的文件。相反,应该使用 /user/joe/foo/bar。
回想一下,在旧世界中无法跨名称节点或集群重命名文件或目录。新世界中也是如此,但有额外的变化。例如,在旧世界中,可以执行以下命令。
rename /user/joe/myStuff /data/foo/bar
如果 /user 和 /data 实际上存储在集群中的不同名称节点上,则此命令在新世界中将不起作用。
HDFS 和其他分布式文件系统通过某种冗余(例如块复制或更复杂的分布式编码)提供数据弹性。然而,现代设置可能由多个 Hadoop 集群、企业文件柜组成,这些集群和文件柜托管在内部和外部。Nfly 装载点使单个逻辑文件可以由多个文件系统同步复制。它专为高达千兆字节的相对较小文件而设计。通常,它是一个单核/单网络链路性能的函数,因为逻辑驻留在使用 ViewFs(例如 FsShell 或 MapReduce 任务)的单个客户端 JVM 中。
考虑以下示例以了解 Nfly 的基本配置。假设我们要将目录 ads 复制到由 URI 表示的三个文件系统上:uri1、uri2 和 uri3。
<property>
<name>fs.viewfs.mounttable.global.linkNfly../ads</name>
<value>uri1,uri2,uri3</value>
</property>
请注意属性名称中有 2 个连续的 ..。它们出现是因为装载点的高级调整设置为空,我们将在后续部分中显示该设置。属性值是由逗号分隔的 URI 列表。
URI 可以指向不同区域的不同集群 hdfs://datacenter-east/ads、s3a://models-us-west/ads、hdfs://datacenter-west/ads,或者在最简单的情况下指向同一文件系统下的不同目录,例如 file:/tmp/ads1、file:/tmp/ads2、file:/tmp/ads3
在全局路径 viewfs://global/ads 下执行的所有修改都会传播到所有目标 URI,如果基础系统可用的话。
例如,如果我们通过 Hadoop shell 创建一个文件
hadoop fs -touchz viewfs://global/ads/z1
我们将在后一个配置中通过本地文件系统找到它
ls -al /tmp/ads*/z1 -rw-r--r-- 1 user wheel 0 Mar 11 12:17 /tmp/ads1/z1 -rw-r--r-- 1 user wheel 0 Mar 11 12:17 /tmp/ads2/z1 -rw-r--r-- 1 user wheel 0 Mar 11 12:17 /tmp/ads3/z1
从全局路径读取由第一个不导致异常的文件系统处理。访问文件系统的顺序取决于它们此时是否可用以及是否存在拓扑顺序。
装入点 linkNfly 可以使用作为键值对逗号分隔列表传递的参数进一步配置。目前支持以下参数。
minReplication=int 确定必须处理写修改且无异常的目标的最小数量,如果低于 nfly 写入失败。将 minReplication 设置得高于目标 URI 的数量是一种配置错误。默认值为 2。
如果 minReplication 低于目标 URI 的数量,我们可能有一些没有最新写入的目标 URI。可以通过使用以下设置控制的更昂贵的读取操作来补偿
readMostRecent=boolean 如果设置为 true,将导致 Nfly 客户端检查所有目标 URI 下的路径,而不仅仅是基于拓扑顺序的第一个路径。在目前所有可用路径中,处理修改时间最新的路径。
repairOnRead=boolean 如果设置为 true,将导致 Nfly 将最新的副本复制到过时的目标,以便以后可以再次从最近的副本廉价读取。
Nfly 试图从“最近”的目标 URI 满足读取。
为此,Nfly 将机架感知的概念扩展到目标 URI 的授权。
Nfly 应用网络拓扑来解析 URI 的授权。在异构设置中,最常用基于脚本的映射。我们可以有一个脚本提供以下拓扑映射
| URI | 拓扑 |
|---|---|
hdfs://datacenter-east/ads |
/us-east/onpremise-hdfs |
s3a://models-us-west/ads |
/us-west/aws |
hdfs://datacenter-west/ads |
/us-west/onpremise-hdfs |
如果目标 URI 没有授权部分,如 file:/,Nfly 会注入客户端的本地节点名称。
<property>
<name>fs.viewfs.mounttable.global.linkNfly.minReplication=3,readMostRecent=true,repairOnRead=false./ads</name>
<value>hdfs://datacenter-east/ads,hdfs://datacenter-west/ads,s3a://models-us-west/ads,file:/tmp/ads</value>
</property>
FileSystem fs = FileSystem.get("viewfs://global/", ...);
FSDataOutputStream out = fs.create("viewfs://global/ads/f1");
out.write(...);
out.close();
上面的代码将导致以下执行。
在每个目标 URI 下创建一个不可见的 _nfly_tmp_f1 文件,即 hdfs://datacenter-east/ads/_nfly_tmp_f1、hdfs://datacenter-west/ads/_nfly_tmp_f1 等。这是通过对底层文件系统调用 create 并返回一个 FSDataOutputStream 对象 out 来完成的,该对象封装了所有四个输出流。
因此,对 out 的每个后续写入都可以转发到每个包装流。
在 out.close 上,所有流都关闭,并且文件从 _nfly_tmp_f1 重命名为 f1。所有文件都接收相同的修改时间,该时间对应于此步骤开始时的客户端系统时间。
如果至少 minReplication 目标已在没有故障的情况下经历了步骤 1-3,则 Nfly 会认为事务在逻辑上已提交;否则,它会尽力尝试清理临时文件。
请注意,由于 4 是尽力而为的步骤,并且客户端 JVM 可能会崩溃且永远不会恢复其工作,因此最好提供某种 cron 作业来清除此类 _nfly_tmp 文件。
当我从非联合世界迁移到联合世界时,我必须跟踪不同卷的名称节点;我该怎么做?
不,您不必这样做。请参阅上面的示例 - 您要么使用相对名称并利用默认文件系统,要么将路径从 hdfs://namenodeCLusterX/foo/bar 更改为 viewfs://clusterX/foo/bar。
如果操作将一些文件从一个名称节点移动到集群内的另一个名称节点,会发生什么情况?
为了解决存储容量问题,操作可能会将文件从一个名称节点移动到另一个名称节点。他们将以一种避免应用程序中断的方式执行此操作。让我们举几个例子。
示例 1:/user 和 /data 在一个名称节点上,后来他们需要在单独的名称节点上处理容量问题。事实上,操作会为 /user 和 /data 创建单独的装入点。在更改之前,/user 和 /data 的装入点将指向同一个名称节点,例如 namenodeContainingUserAndData。操作将更新装入表,以便将装入点分别更改为 namenodeContaingUser 和 namenodeContainingData。
示例 2:所有项目都安装在一个 namenode 上,但后来需要两个或更多个 namenode。ViewFs 允许挂载类似于 /project/foo 和 /project/bar 的内容。这允许更新挂载表以指向相应的 namenode。
每个 core-site.xml 中的挂载表还是单独的文件?
计划是将挂载表保存在单独的文件中,并让 core-site.xml xinclude 它。虽然可以在本地将这些文件保存在每台机器上,但最好使用 HTTP 从中心位置访问它。
配置应该仅包含一个集群还是所有集群的挂载表定义?
配置应该包含所有集群的挂载定义,因为需要访问其他集群中的数据,例如 distcp。
鉴于操作可能会随着时间的推移而更改挂载表,实际读取挂载表的时间是什么时候?
当作业提交到集群时,将读取挂载表。core-site.xml 中的 XInclude 在作业提交时展开。这意味着如果更改了挂载表,则需要重新提交作业。由于这个原因,我们希望实现合并挂载,这将极大地减少更改挂载表的需要。此外,我们希望通过另一种机制读取挂载表,该机制将在将来的作业启动时间初始化。
JobTracker(或 Yarn 的资源管理器)本身是否会使用 ViewFs?
不会,它不需要。NodeManager 也不需要。
ViewFs 是否只允许在顶级进行挂载?
不;它更通用。例如,可以挂载 /user/joe 和 /user/jane。在这种情况下,将在挂载表中为 /user 创建一个内部只读目录。/user 上的所有操作都是有效的,但 /user 是只读的。
一个应用程序在集群之间运行,并且需要持久存储文件路径。它应该存储哪些路径?
您应该存储 viewfs://cluster/path 类型的路径名称,就像在运行应用程序时使用的一样。只要操作以透明的方式移动数据,这就能让您免受集群内 namenode 中数据移动的影响。如果数据从一个集群移动到另一个集群,它并不能让您免受影响;无论如何,较早的(联邦之前的)世界并不能保护您免受跨集群的此类数据移动的影响。
委派令牌呢?
自动处理您提交作业的集群(包括该集群的挂载表的挂载卷)、以及输入和输出路径到您的 MapReduce 作业(包括通过指定输入和输出路径的挂载表挂载的所有卷)的委派令牌。此外,还有一种方法可以为特殊情况向基本集群配置添加其他委派令牌。
View 文件系统装载点是一个基于键值对的映射系统。对于映射配置可以抽象为规则的用户用例,它并不友好。例如,用户希望为每个用户提供一个 GCS 存储分区,并且总共有数千个用户。基于旧键值对的方法由于以下几个原因效果不佳
装载表由文件系统客户端使用。将配置传播到所有客户端需要成本,如果可能,我们应该避免这样做。View 文件系统过载方案指南可以通过集中式装载表管理来帮助分发。但是,装载表在每次更改时仍然必须更新。如果提供基于规则的装载表,则可以极大地避免更改。
客户端必须了解装载表中的所有键值对。当可装载项增长到数千项时,这不是理想的情况。例如,即使用户只需要一个,也可能会初始化数千个文件系统。而且配置本身在规模上会变得臃肿。
在基于键值对的装载表中,View 文件系统将每个装载点都视为一个分区。有几个文件系统 API 将导致对所有分区进行操作。例如,有一个具有多个装载点的 HDFS 集群。用户希望运行“hadoop fs -put file viewfs://hdfs.namenode.apache.org/tmp/” cmd 将数据从本地磁盘复制到我们的 HDFS 集群。该 cmd 将触发 ViewFileSystem 调用 setVerifyChecksum() 方法,该方法将为每个装载点初始化文件系统。对于基于正则表达式规则的装载表条目,我们无法在解析之前知道对应的路径是什么。因此,在这些情况下将忽略基于正则表达式的装载表条目。文件系统 (ChRootedFileSystem) 将在访问时创建。但是底层文件系统将被 ViewFileSystem 的内部缓存缓存。
<property>
<name>fs.viewfs.rename.strategy</name>
<value>SAME_FILESYSTEM_ACROSS_MOUNTPOINT</value>
</property>
以下是基本正则表达式挂载点配置示例。${username} 是 Java 正则表达式中的命名捕获组。
<property>
<name>fs.viewfs.mounttable.hadoop-nn.linkRegx./^(?<username>\\w+)</name>
<value>gs://${username}.hadoop.apache.org/</value>
</property>
解析示例。
viewfs://hadoop-nn/user1/dir1 => gs://user1.hadoop.apache.org/dir1 viewfs://hadoop-nn/user2 => gs://user2.hadoop.apache.org/
src/key 的格式为
fs.viewfs.mounttable.${VIEWNAME}.linkRegx.${REGEX_STR}
拦截器是一种在解析过程中修改源或目标的机制。它是可选的,可用于满足替换特定字符或替换某些单词等用户案例。拦截器仅适用于正则表达式挂载点。RegexMountPointResolvedDstPathReplaceInterceptor 是目前唯一的内置拦截器。
以下是设置了 RegexMountPointResolvedDstPathReplaceInterceptor 的正则表达式挂载点条目示例。
<property>
<name>fs.viewfs.mounttable.hadoop-nn.linkRegx.replaceresolveddstpath:_:-#./^(?<username>\\w+)</name>
<value>gs://${username}.hadoop.apache.org/</value>
</property>
replaceresolveddstpath:_:- 是拦截器设置。“replaceresolveddstpath” 是拦截器类型,“_” 是要替换的字符串,“-” 是替换后的字符串。
解析示例。
viewfs://hadoop-nn/user_ad/dir1 => gs://user-ad.hadoop.apache.org/dir1 viewfs://hadoop-nn/user_ad_click => gs://user-ad-click.hadoop.apache.org/
src/key 的格式为
fs.viewfs.mounttable.${VIEWNAME}.linkRegx.${REGEX_STR}
fs.viewfs.mounttable.${VIEWNAME}.linkRegx.${interceptorSettings}#.${srcRegex}
通常,用户无需定义挂载表或 core-site.xml 即可使用挂载表。这是由运维人员完成的,并且正确的配置已在正确的网关机器上设置,就像今天对 core-site.xml 所做的那样。
挂载表可以在 core-site.xml 中描述,但最好在 core-site.xml 中使用间接引用来引用单独的配置文件,例如 mountTable.xml。将以下配置元素添加到 core-site.xml 以引用 mountTable.xml
<configuration xmlns:xi="http://www.w3.org/2001/XInclude"> <xi:include href="mountTable.xml" /> </configuration>
在文件 mountTable.xml 中,有一个挂载表“ClusterX”的定义,用于由三个名称节点管理的三个命名空间卷的联合的假设集群
此处 /home 和 /tmp 位于由名称节点 nn1-clusterx.example.com:8020 管理的命名空间中,项目 /foo 和 /bar 托管在联合集群的其他名称节点上。主目录基本路径设置为 /home,以便每个用户都可以使用在 FileSystem/FileContext 中定义的 getHomeDirectory() 方法访问其主目录。
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.homedir</name>
<value>/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./home</name>
<value>hdfs://nn1-clusterx.example.com:8020/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn1-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/foo</name>
<value>hdfs://nn2-clusterx.example.com:8020/projects/foo</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/bar</name>
<value>hdfs://nn3-clusterx.example.com:8020/projects/bar</value>
</property>
</configuration>