
本指南概述了 YARN 的 ResourceManager 的高可用性,并详细介绍了如何配置和使用此功能。ResourceManager (RM) 负责跟踪群集中的资源,并调度应用程序(例如,MapReduce 作业)。在 Hadoop 2.4 之前,ResourceManager 是 YARN 群集中的单点故障。高可用性功能以活动/备用 ResourceManager 对的形式增加了冗余,以消除此单点故障。
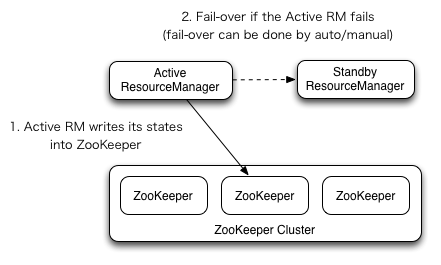
ResourceManager HA 通过活动/备用架构实现 - 在任何时间点,一个 RM 处于活动状态,一个或多个 RM 处于备用模式,等待在活动 RM 发生任何情况时接管。切换到活动状态的触发器来自管理员(通过 CLI)或在启用自动故障转移时通过集成的故障转移控制器。
当未启用自动故障转移时,管理员必须手动将其中一个 RM 过渡到活动状态。要从一个 RM 故障转移到另一个 RM,他们首先需要将活动 RM 过渡到备用状态,并将备用 RM 过渡到活动状态。所有这些操作都可以使用“yarn rmadmin”CLI 完成。
RM 有一个选项来嵌入基于 Zookeeper 的 ActiveStandbyElector,以决定哪个 RM 应为活动状态。当活动状态宕机或变得无响应时,将自动选举另一个 RM 为活动状态,然后接管。请注意,无需运行单独的 ZKFC 守护程序,因为 HDFS 的情况也是如此,因为嵌入在 RM 中的 ActiveStandbyElector 充当故障检测器和领导者选举器,而不是单独的 ZKFC 守护程序。
当有多个 RM 时,客户端和节点使用的配置 (yarn-site.xml) 应列出所有 RM。客户端、应用程序主服务器 (AM) 和节点管理器 (NM) 尝试以循环方式连接到 RM,直到它们命中活动 RM。如果活动状态宕机,它们将恢复循环轮询,直到命中“新”活动状态。此默认重试逻辑实现为 org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider。您可以通过实现 org.apache.hadoop.yarn.client.RMFailoverProxyProvider 并将 yarn.client.failover-proxy-provider 的值设置为类名来覆盖逻辑。在非 ha 模式下运行时,请改而设置 yarn.client.failover-no-ha-proxy-provider 的值
启用ResourceManager 重新启动后,提升为活动状态的 RM 将加载 RM 内部状态,并尽可能地从上一个活动状态中断开的地方继续操作,具体取决于 RM 重新启动功能。为之前提交给 RM 的每个受管应用程序生成一个新尝试。应用程序可以定期检查点以避免丢失任何工作。活动/备用 RM 都必须可见状态存储。目前,有两种用于持久性的 RMStateStore 实现 - FileSystemRMStateStore 和 ZKRMStateStore。ZKRMStateStore 隐式允许在任何时间点对单个 RM 进行写访问,因此建议在 HA 集群中使用此存储。使用 ZKRMStateStore 时,无需单独的隔离机制来解决多个 RM 可能同时承担活动角色的潜在脑裂情况。使用 ZKRMStateStore 时,建议不要在 Zookeeper 集群上设置“zookeeper.DigestAuthenticationProvider.superDigest”属性,以确保 zookeeper 管理员无法访问 YARN 应用程序/用户凭据信息。
大多数故障转移功能都可以使用各种配置属性进行调整。以下是必需/重要的属性列表。yarn-default.xml 包含一个完整的旋钮列表。有关更多信息(包括默认值),请参见yarn-default.xml。另请参阅ResourceManager 重新启动文档,了解有关设置状态存储的说明。
| 配置属性 | 描述 |
|---|---|
hadoop.zk.address |
ZK 仲裁组的地址。用于状态存储和嵌入式领导者选举。 |
yarn.resourcemanager.ha.enabled |
启用 RM HA。 |
yarn.resourcemanager.ha.rm-ids |
RM 的逻辑 ID 列表。例如,“rm1、rm2”。 |
yarn.resourcemanager.hostname.rm-id |
对于每个rm-id,指定 RM 对应的主机名。或者,可以设置每个 RM 的服务地址。 |
yarn.resourcemanager.address.rm-id |
对于每个rm-id,指定客户端提交作业的主机:端口。如果设置,将覆盖yarn.resourcemanager.hostname.rm-id中设置的主机名。 |
yarn.resourcemanager.scheduler.address.rm-id |
对于每个rm-id,指定 ApplicationMasters 获取资源的调度程序主机:端口。如果设置,将覆盖yarn.resourcemanager.hostname.rm-id中设置的主机名。 |
yarn.resourcemanager.resource-tracker.address.rm-id |
对于每个rm-id,指定 NodeManagers 连接的主机:端口。如果设置,将覆盖yarn.resourcemanager.hostname.rm-id中设置的主机名。 |
yarn.resourcemanager.admin.address.rm-id |
对于每个rm-id,指定管理命令的主机:端口。如果设置,将覆盖yarn.resourcemanager.hostname.rm-id中设置的主机名。 |
yarn.resourcemanager.webapp.address.rm-id |
对于每个rm-id,指定与 RM Web 应用程序相对应的 host:port。如果您将 yarn.http.policy 设置为 HTTPS_ONLY,则不需要此项。如果设置,则会覆盖 yarn.resourcemanager.hostname.rm-id 中设置的主机名。 |
yarn.resourcemanager.webapp.https.address.rm-id |
对于每个rm-id,指定与 RM https Web 应用程序相对应的 host:port。如果您将 yarn.http.policy 设置为 HTTP_ONLY,则不需要此项。如果设置,则会覆盖 yarn.resourcemanager.hostname.rm-id 中设置的主机名。 |
yarn.resourcemanager.ha.id |
标识集合中的 RM。此项是可选的;但是,如果设置,则管理员必须确保所有 RM 在配置中都有自己的 ID。 |
yarn.resourcemanager.ha.automatic-failover.enabled |
启用自动故障转移;默认情况下,仅在启用 HA 时启用。 |
yarn.resourcemanager.ha.automatic-failover.embedded |
在启用自动故障转移时,使用嵌入式领导者选举器选择活动 RM。默认情况下,仅在启用 HA 时启用。 |
yarn.resourcemanager.cluster-id |
标识集群。选举器使用此项来确保 RM 不会接管另一个集群的活动状态。 |
yarn.client.failover-proxy-provider |
客户端、AM 和 NM 用于故障转移到活动 RM 的类。 |
yarn.client.failover-no-ha-proxy-provider |
客户端、AM 和 NM 用于故障转移到活动 RM 的类,在非 HA 模式下运行时 |
yarn.client.failover-max-attempts |
FailoverProxyProvider 应尝试故障转移的最大次数。 |
yarn.client.failover-sleep-base-ms |
用于计算故障转移之间指数延迟的睡眠基数(以毫秒为单位)。 |
yarn.client.failover-sleep-max-ms |
故障转移之间的最大睡眠时间(以毫秒为单位)。 |
yarn.client.failover-retries |
连接到 ResourceManager 的每次尝试的重试次数。 |
yarn.client.failover-retries-on-socket-timeouts |
在套接字超时时连接到 ResourceManager 的每次尝试的重试次数。 |
以下是 RM 故障转移的最小设置示例。
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>master2:8088</value> </property> <property> <name>hadoop.zk.address</name> <value>zk1:2181,zk2:2181,zk3:2181</value> </property>
yarn rmadmin 有一些特定于 HA 的命令选项,用于检查 RM 的运行状况/状态,并转换到活动/备用状态。HA 的命令将 yarn.resourcemanager.ha.rm-ids 设置的 RM 服务 ID 作为参数。
$ yarn rmadmin -getServiceState rm1 active $ yarn rmadmin -getServiceState rm2 standby
如果启用自动故障转移,则不能使用手动转换命令。虽然您可以通过 –forcemanual 标志覆盖此项,但您需要谨慎。
$ yarn rmadmin -transitionToStandby rm1 Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@1d8299fd Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state. If you are very sure you know what you are doing, please specify the forcemanual flag.
有关更多详细信息,请参见 YarnCommands。
假设备用 RM 已启动并正在运行,则备用 RM 会自动将所有 Web 请求重定向到活动 RM,但“关于”页面除外。
假设备用 RM 正在运行,当在备用 RM 上调用 ResourceManager REST API 中描述的 RM Web 服务时,它们会自动重定向到活动 RM。
如果您在负载均衡器(例如 Azure 或 AWS )后面运行一组 ResourceManager,并且希望负载均衡器指向活动 RM,您可以使用 /isActive HTTP 端点作为运行状况探测。http://RM_HOSTNAME/isActive 如果 RM 处于活动 HA 状态,将返回 200 状态代码响应,否则返回 405。