
测功机是一个用于测试 Hadoop 的 HDFS NameNode 性能的工具。其目的是通过针对生产文件系统映像初始化 NameNode 并重放通过 NameNode 审计日志等方式收集的生产工作负载,来提供一个真实的环境。这允许重放一个工作负载,该工作负载不仅在特征上类似于生产中遇到的工作负载,而且实际上是相同的。
测功机会启动一个 YARN 应用程序,该应用程序启动一个 NameNode 和可配置数量的 DataNode,将整个 HDFS 集群模拟为一个应用程序。还有一个额外的 workload 作业作为 MapReduce 作业运行,该作业接受审计日志作为输入,并使用其中包含的信息向 NameNode 提交匹配的请求,从而对服务施加负载。
测功机可以在不同的 Hadoop 版本或不同的配置上执行相同的负载,从而允许在无需部署到真正的超大规模集群的情况下大规模地测试配置调整和代码更改。
在整个文档中,我们将使用“Dyno-HDFS”、“Dyno-NN”和“Dyno-DN”分别指代 HDFS 集群、NameNode 和 DataNodes(分别位于 Dynamometer 应用程序内部启动)。未经限定使用的 HDFS、YARN 和 NameNode 等术语指代 Dynamometer 运行在其上的现有基础架构。
有关 Dynamometer 工作原理的更多详细信息(相对于如何使用它),请参阅本页末尾的架构部分。
Dynamometer 基于 YARN 应用程序,因此执行需要一个现有的 YARN 集群。它还需要一个配套的 HDFS 实例来存储一些用于通信的临时文件。
Dynamometer 由三个主要组件组成,每个组件都在其自己的模块中
dynamometer-infra):这是启动 Dyno-HDFS 集群的 YARN 应用程序。dynamometer-workload):这是重播审计日志的 MapReduce 作业。dynamometer-blockgen):这是一个用于为每个 Dyno-DN 生成输入文件的 MapReduce 作业;其执行是运行基础架构应用程序的先决步骤。所有这些组件的已编译版本都将包含在标准 Hadoop 发行版中。您可以在 share/hadoop/tools/dynamometer 中的打包发行版中找到它们。
在启动 Dynamometer 应用程序之前,必须完成一些设置步骤,指示 Dynamometer 使用哪些配置、使用哪个版本、加载时使用哪个 fsimage 等。这些步骤可以执行一次以将所有内容就位,然后可以对它们执行许多 Dynamometer 执行,并进行微小的调整以测量差异。
下面讨论的脚本可以在发行版的 share/hadoop/tools/dynamometer/dynamometer-{infra,workload,blockgen}/bin 目录中找到。相应的 Java JAR 文件可以在 share/hadoop/tools/lib/ 目录中找到。下面对 bin 文件的引用假定当前工作目录为 share/hadoop/tools/dynamometer。
在启动第一个 Dyno-HDFS 集群之前需要执行一些步骤
从您的 NameNode 收集 fsimage 和相关文件。这将包括 NameNode 在检查点过程中创建的 fsimage_TXID 文件、包含图像的 md5 哈希的 fsimage_TXID.md5、包含一些元数据的 VERSION 文件以及可以使用离线图像查看器从 fsimage 生成的 fsimage_TXID.xml 文件
hdfs oiv -i fsimage_TXID -o fsimage_TXID.xml -p XML
如果您有一个辅助/备用 NameNode,建议您从该 NameNode 中收集这些文件,以避免给您的活动 NameNode 增加额外负载。
所有这些文件都必须放置在 HDFS 中的某个位置,以便各种作业能够访问它们。它们都应位于同一文件夹中,例如 hdfs:///dyno/fsimage。
所有这些步骤都可以使用 upload-fsimage.sh 脚本自动完成,例如。
./dynamometer-infra/bin/upload-fsimage.sh 0001 hdfs:///dyno/fsimage
其中 0001 是所需 fsimage 的事务 ID。有关更多详细信息,请参阅脚本的使用信息。
收集要用于启动 Dyno-NN 和 -DN 的 Hadoop 发行版 tar 包。例如,如果针对 Hadoop 3.0.2 进行测试,请使用 hadoop-3.0.2.tar.gz。此发行版包含 Dynamometer 不需要的几个组件(例如 YARN),因此为了减小其大小,您可以选择使用 create-slim-hadoop-tar.sh 脚本
./dynamometer-infra/bin/create-slim-hadoop-tar.sh hadoop-VERSION.tar.gz
Hadoop tar 可以存在于 HDFS 上,也可以存在于将从中运行客户端的本地位置。其路径将通过 -hadoop_binary_path 参数提供给客户端。
或者,如果您使用 -hadoop_version 参数,则可以简单地指定您想要针对哪个版本运行(例如“3.0.2”),客户端将尝试从 Apache 镜像自动下载它。有关更多详细信息,请参阅客户端的使用信息。
准备一个配置目录。您需要使用标准 Hadoop 配置布局指定一个配置目录,例如它应包含 etc/hadoop/*-site.xml。这决定了 Dyno-NN 和 -DN 将使用什么配置启动。必须修改才能使 Dynamometer 正常工作的配置(例如 fs.defaultFS 或 dfs.namenode.name.dir)将在执行时被覆盖。如果在本地可用,这可以是一个目录,否则可以是本地或远程(HDFS)存储上的存档文件。
这将使用 fsimage_TXID.xml 文件生成每个 Dyno-DN 应向 Dyno-NN 通告的块列表。它作为 MapReduce 作业运行。
./dynamometer-blockgen/bin/generate-block-lists.sh
-fsimage_input_path hdfs:///dyno/fsimage/fsimage_TXID.xml
-block_image_output_dir hdfs:///dyno/blocks
-num_reducers R
-num_datanodes D
在此示例中,上面上传的 XML 文件用于生成块列表到 hdfs:///dyno/blocks。作业使用 R 个还原器,并生成 D 个块列表 - 这将确定在 Dyno-HDFS 集群中启动多少个 Dyno-DN。
仅当您打算使用测功机的审计跟踪重放功能时,此步骤才必需;如果您只想启动 Dyno-HDFS 集群,则可以跳到下一部分。
审计跟踪重放接受每个映射器一个输入文件,并且当前支持两种输入格式,可通过 auditreplay.command-parser.class 配置进行配置。将自动为启动时指定的审计日志目录中的每个审计日志文件创建一个映射器。
默认格式为直接格式,org.apache.hadoop.tools.dynamometer.workloadgenerator.audit.AuditLogDirectParser。它接受标准配置审计记录器生成的文件格式,例如以下行
1970-01-01 00:00:42,000 INFO FSNamesystem.audit: allowed=true ugi=hdfs ip=/127.0.0.1 cmd=open src=/tmp/foo dst=null perm=null proto=rpc
使用此格式时,您还必须指定 auditreplay.log-start-time.ms,它应该是审计跟踪的开始时间(自 Unix 纪元以来的毫秒数)。所有映射器都需要同意一个开始时间。例如,如果上述行是第一个审计事件,则您将指定 auditreplay.log-start-time.ms=42000。在文件中,审计日志必须按时间戳升序排列。
另一种受支持的格式是 org.apache.hadoop.tools.dynamometer.workloadgenerator.audit.AuditLogHiveTableParser。它接受 Hive 查询生成的文件格式,按顺序输出字段
relativeTimestamp:事件时间偏移量,以毫秒为单位,从跟踪开始ugi:提交用户的用户信息command:命令名称,例如“open”source:源路径dest:目标路径sourceIP:事件的源 IP假设您的审计日志在 Hive 中可用,则可以通过类似以下内容的 Hive 查询生成
INSERT OVERWRITE DIRECTORY '${outputPath}'
SELECT (timestamp - ${startTimestamp} AS relativeTimestamp, ugi, command, source, dest, sourceIP
FROM '${auditLogTableLocation}'
WHERE timestamp >= ${startTimestamp} AND timestamp < ${endTimestamp}
DISTRIBUTE BY src
SORT BY relativeTimestamp ASC;
您可能会注意到,在上面显示的 Hive 查询中,有一个 DISTRIBUTE BY src 子句,它表示输出文件应按调用者的源 IP 进行分区。这样做是为了尝试维护来自单个客户端的请求的更紧密顺序。测功机不保证严格的顺序操作,即使在分区内也是如此,但通常在分区内比跨分区更紧密地维护顺序。
无论您使用 Hive 还是原始审计日志,都必须根据执行工作负载重放所需的并发客户端数量对审计日志进行分区。使用源 IP 作为分区键是一种方法,具有上面讨论的潜在优势,但任何分区方案都应该运行得很好。
完成上述设置步骤后,您就可以启动一个 Dyno-HDFS 集群并针对其重放一些工作负载了!
启动 Dyno-HDFS YARN 应用程序的客户端可以在 Dyno-HDFS 集群完全启动后选择启动工作负载重放作业。这会将每次重放变成客户端的单次执行,从而可以轻松测试各种配置。您还可以将两者分开启动以获得更多控制。同样,也可以为 Dynamometer/YARN 不控制的外部 NameNode 启动 Dyno-DN。这对于测试尚未受支持的 NameNode 配置(例如 HA NameNode)很有用。您可以通过将 -namenode_servicerpc_addr 参数传递给基础设施应用程序来实现此目的,该参数的值指向外部 NameNode 的服务 RPC 地址。
首先启动基础设施应用程序以开始内部 HDFS 集群的启动,例如:
./dynamometer-infra/bin/start-dynamometer-cluster.sh
-hadoop_binary_path hadoop-3.0.2.tar.gz
-conf_path my-hadoop-conf
-fs_image_dir hdfs:///fsimage
-block_list_path hdfs:///dyno/blocks
这演示了必需的参数。您可以使用 -help 标志运行此命令以查看进一步的使用信息。
客户端将跟踪 Dyno-NN 的启动进度以及它认为有多少个 Dyno-DN 处于活动状态。当 Dyno-NN 退出安全模式并准备好使用时,它将通过日志进行通知。
此时,可以启动工作负载作业(仅映射的 MapReduce 作业),例如:
./dynamometer-workload/bin/start-workload.sh
-Dauditreplay.input-path=hdfs:///dyno/audit_logs/
-Dauditreplay.output-path=hdfs:///dyno/results/
-Dauditreplay.num-threads=50
-nn_uri hdfs://namenode_address:port/
-start_time_offset 5m
-mapper_class_name AuditReplayMapper
工作负载生成类型是可配置的;AuditReplayMapper 重放之前讨论过的审计日志跟踪。AuditReplayMapper 通过配置进行配置;auditreplay.input-path、auditreplay.output-path 和 auditreplay.num-threads 是必需的,用于指定审计日志文件的输入路径、结果的输出路径以及每个映射任务的线程数。将启动与 input-path 中的文件数相等数量的映射任务;每个任务将读取其中一个输入文件,并使用 num-threads 线程重放该文件中包含的事件。尽最大努力以与最初发生的相同速度忠实地重放审计日志事件(可以选择通过指定 auditreplay.rate-factor 来调整此速度,这是一个针对重放速率的乘法因子,例如使用 2.0 以两倍于原始速度重放事件)。
AuditReplayMapper 将以 CSV 格式将基准测试结果输出到输出目录中的文件 part-r-00000。每行都采用 user,type,operation,numops,cumulativelatency 格式,例如 hdfs,WRITE,MKDIRS,2,150。
要让基础设施应用程序客户端自动启动工作负载,需要将工作负载作业的参数传递给基础设施脚本。目前,仅 AuditReplayMapper 支持这种方式。要使用与上述相同的参数启动集成应用程序,可以使用以下内容
./dynamometer-infra/bin/start-dynamometer-cluster.sh
-hadoop_binary hadoop-3.0.2.tar.gz
-conf_path my-hadoop-conf
-fs_image_dir hdfs:///fsimage
-block_list_path hdfs:///dyno/blocks
-workload_replay_enable
-workload_input_path hdfs:///dyno/audit_logs/
-workload_output_path hdfs:///dyno/results/
-workload_threads_per_mapper 50
-workload_start_delay 5m
以这种方式运行时,客户端将在工作负载完成后自动处理拆除 Dyno-HDFS 集群。要查看受支持参数的完整列表,请使用 -help 标志运行此命令。
Dynamometer 作为 YARN 上的应用程序实现。Dynamometer 应用程序中有三个主要参与者
驱动程序中封装的逻辑使用户能够使用单个命令执行 Dynamometer 的完整测试,从而可以执行诸如扫描不同参数以查找最佳配置之类的操作。
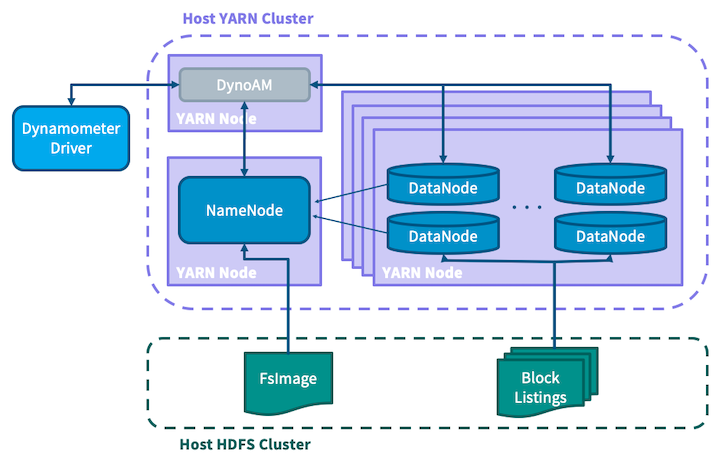
基础设施应用程序被编写为本机 YARN 应用程序,其中启动单个 NameNode 和大量 DataNode,并将它们连接在一起以创建完全模拟的 HDFS 集群。为了让 Dynamometer 提供极其真实的场景,有必要拥有一个从 NameNode 的角度来看包含与生产集群相同信息的集群。这就是上面描述的设置步骤首先涉及从生产 NameNode 收集 FsImage 文件并将其放置在主机 HDFS 集群上的原因。为了避免必须复制整个集群的块,Dynamometer 利用了以下事实:存储在块中的实际数据与 NameNode 无关,NameNode 只知道块元数据。Dynamometer 的 blockgen 作业首先使用离线图像查看器将 FsImage 转换为 XML,然后对其进行解析以提取每个块的元数据,然后对这些信息进行分区,然后再将其放置在 HDFS 上供模拟的 DataNode 使用。SimulatedFSDataset 用于绕过 DataNode 存储层,仅存储从上一步中提取的信息加载的块元数据。此方案允许 Dynamometer 将许多模拟的 DataNode 打包到每个物理节点上,因为元数据的大小比数据本身小很多个数量级。
要创建与生产环境相匹配的压力测试,Dynamometer 需要一种方法来收集有关生产工作负载的信息。为此,使用了 HDFS 审计日志,其中包含针对 NameNode 的所有面向客户端操作的真实记录。通过重播此审计日志以重新创建客户端负载,并运行模拟数据节点以重新创建集群管理负载,Dynamometer 能够提供生产 NameNode 条件的真实模拟。
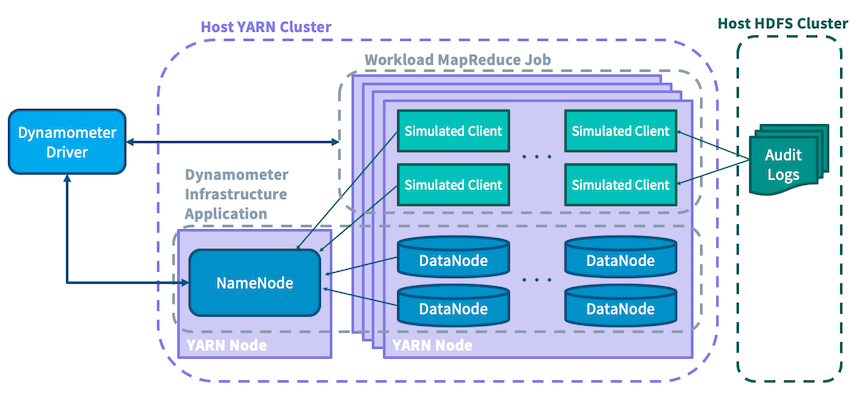
负载很重的 NameNode 每秒可以处理数万个操作;为了引起这样的负载,Dynamometer 需要大量客户端来提交请求。为了确保每个请求都具有与其原始提交相同的效果和性能影响,Dynamometer 尝试以保留其原始顺序的方式发出相关请求(例如,目录创建后跟该目录的列表)。出于这个原因,建议按源 IP 地址对审计日志文件进行分区,假设源自同一主机的请求比源自不同主机的请求具有更紧密的因果关系。为了简单起见,压力测试作业被写成仅映射的 MapReduce 作业,其中每个映射器使用分区审计日志文件,并针对模拟的 NameNode 重播其中包含的命令。在执行过程中,会收集有关重播的统计信息,例如不同类型请求的延迟。
要查看有关 Dynamometer 的更多信息,您可以查看宣布其初始发布的博客文章或此演示文稿。