
YARN 时间线服务 v.2 是时间线服务器的下一个主要迭代,紧随 v.1 和 v.1.5。V.2 的创建是为了解决 v.1 的两个主要挑战。
V.1 仅限于单个写入器/读取器和存储实例,并且无法很好地扩展到小型集群之外。V.2 使用更具可伸缩性的分布式写入器架构和可伸缩的后端存储。
YARN 时间线服务 v.2 将数据的收集(写入)与数据的服务(读取)分开。它使用分布式收集器,基本上每个 YARN 应用程序一个收集器。读取器是独立的实例,专门通过 REST API 提供查询服务。
YARN 时间线服务 v.2 选择 Apache HBase 作为主要的后端存储,因为 Apache HBase 可以很好地扩展到很大规模,同时保持良好的读取和写入响应时间。
在很多情况下,用户对“流”级别或 YARN 应用程序的逻辑组中的信息感兴趣。启动一组或一系列 YARN 应用程序以完成逻辑应用程序更为常见。Timeline Service v.2 明确支持流的概念。此外,它还支持在流级别聚合指标。
此外,配置和指标等信息被视为一等公民并受到支持。
下图说明了对流进行建模的不同 YARN 实体之间的关系。
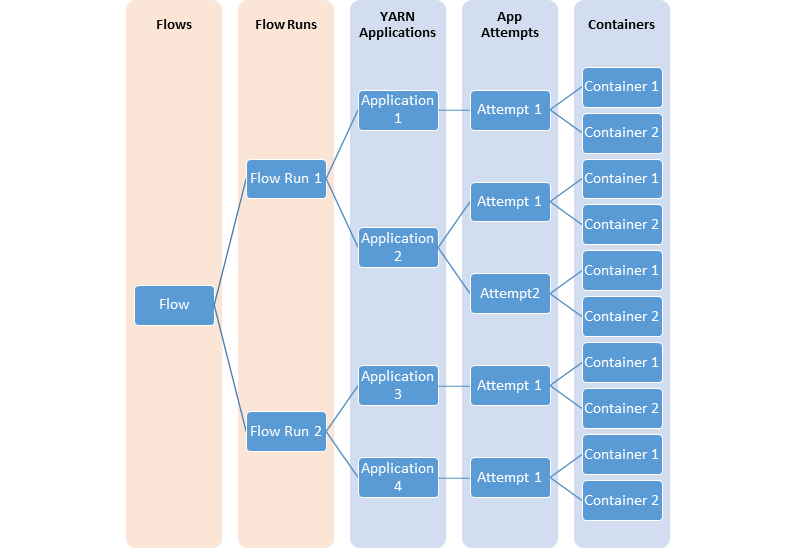
YARN Timeline Service v.2 使用一组收集器(写入器)将数据写入后端存储。这些收集器是分布式的,并与它们专用的应用程序主控共置。除资源管理器时间线收集器外,属于该应用程序的所有数据都将发送到应用程序级别时间线收集器。
对于给定的应用程序,应用程序主控可以将应用程序的数据写入共置时间线收集器(在本版本中是 NM 辅助服务)。此外,运行应用程序容器的其他节点的节点管理器也会将数据写入运行应用程序主控的节点上的时间线收集器。
资源管理器还维护其自己的时间线收集器。它仅发出 YARN 通用生命周期事件,以保持其写入量合理。
时间线读取器是独立于时间线收集器的单独守护进程,它们专门通过 REST API 提供查询服务。
下图说明了高级别的设计。
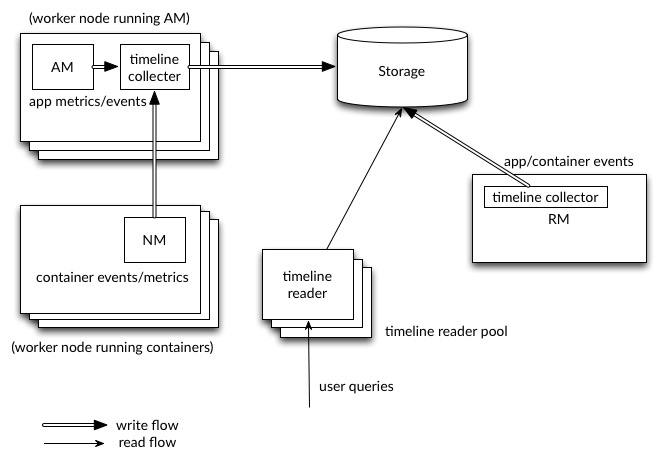
完整的端到端写入和读取流是可行的,Apache HBase 作为后端。您应该能够开始生成数据。启用后,将发布所有 YARN 通用事件以及 YARN 系统指标,如 CPU 和内存。此外,包括 Distributed Shell 和 MapReduce 在内的一些应用程序可以将每个框架的数据写入 YARN Timeline Service v.2。
访问数据的基本模式是通过 REST。REST API 带有大量有用且灵活的查询模式(有关详细信息,请参见下文)。YARN Client 已与 ATSv2 集成。如果 ResouceManager 中不存在详细信息,这将能够从 TimelineReader 中获取应用程序/尝试/容器报告。
收集器(写入器)当前作为辅助服务嵌入在节点管理器中。资源管理器也有其专用的进程内收集器。读取器当前是单个实例。目前,无法在 YARN 应用程序的上下文之外写入 Timeline Service(即没有群集外客户端)。
支持端到端 Kerberos 身份验证。与 HBase 的所有通信都可以进行 Kerberos 认证。有关配置,请参阅 安全配置。已根据可配置的白名单(其中包含可以读取时间线数据的用户和组)添加了对简单授权的支持。默认情况下,集群管理员被允许读取时间线数据。
当 YARN Timeline Service v.2 被禁用时,可以预期不会对任何其他现有功能产生功能或性能影响。
路线图包括
v.2 中引入的新配置参数以粗体标记。
| 配置属性 | 说明 |
|---|---|
yarn.timeline-service.enabled |
向客户端指示 Timeline 服务是否已启用。如果已启用,应用程序使用的 TimelineClient 库将实体和事件发布到 Timeline 服务器。默认为 false。 |
yarn.timeline-service.version |
指示正在运行的时间线服务的当前版本。例如,如果“yarn.timeline-service.version”为 1.5,并且“yarn.timeline-service.enabled”为 true,则表示集群将且必须启动时间线服务 v.1.5(并且没有其他服务)。在客户端中,如果客户端使用相同版本的时间线服务,则必须成功。尽管如此,如果客户端选择使用较低版本,则结果可能会有所不同,具体取决于版本之间兼容性故事的稳健程度。默认为 1.0f。 |
yarn.timeline-service.writer.class |
后端存储写入器的类。默认为 HBase 存储写入器。 |
yarn.timeline-service.reader.class |
后端存储读取器的类。默认为 HBase 存储读取器。 |
yarn.system-metrics-publisher.enabled |
控制 RM 和 NM 是否在 Timeline 服务上发布纱线系统指标的设置。默认为 false。 |
yarn.timeline-service.schema.prefix |
hbase 表的模式前缀。默认为“prod”。 |
| 配置属性 | 说明 |
|---|---|
yarn.timeline-service.hostname |
Timeline 服务 Web 应用程序的主机名。默认为 0.0.0.0 |
yarn.timeline-service.reader.webapp.address |
Timeline Reader Web 应用程序的 http 地址。默认为 ${yarn.timeline-service.hostname}:8188。 |
yarn.timeline-service.reader.webapp.https.address |
Timeline Reader Web 应用程序的 https 地址。默认为 ${yarn.timeline-service.hostname}:8190。 |
yarn.timeline-service.reader.bind-host |
时间线阅读器将绑定的实际地址。如果设置了此可选地址,阅读器服务器将绑定到此地址和 yarn.timeline-service.reader.webapp.address 中指定的端口。通过将此地址设置为 0.0.0.0,最适合让此服务侦听所有接口。 |
yarn.timeline-service.hbase.configuration.file |
用于连接到时间线服务 hbase 集群的 hbase-site.xml 配置文件的可选 URL。如果为空或未指定,则 HBase 配置将从类路径加载。指定后,指定配置文件中的值将覆盖类路径中存在的值。默认为 null。 |
yarn.timeline-service.writer.flush-interval-seconds |
控制时间线收集器刷新时间线编写器的频率的设置。默认为 60。 |
yarn.timeline-service.app-collector.linger-period.ms |
在应用程序主容器完成后,应用程序收集器在 NM 中保持活动状态的时间段。默认为 60000(60 秒)。 |
yarn.timeline-service.timeline-client.number-of-async-entities-to-merge |
时间线 V2 客户端尝试合并如此多的异步实体(如果可用),然后调用 REST ATS V2 API 进行提交。默认为 10。 |
yarn.timeline-service.hbase.coprocessor.app-final-value-retention-milliseconds |
控制已完成应用程序的指标的最终值在合并到流和中之前保留多长时间的设置。默认为 259200000(3 天)。这应在 HBase 集群中设置。 |
yarn.rm.system-metrics-publisher.emit-container-events |
控制是否由 RM 将 yarn 容器指标发布到时间线服务器的设置。此配置设置适用于 ATS V2。默认为 false。 |
yarn.nodemanager.emit-container-events |
由 NM 控制是否将纱线容器指标发布到时间线服务器的设置。此配置设置适用于 ATS V2。默认为 true。 |
将 yarn.timeline-service.http-authentication.type 设置为 kerberos 即可启用安全,之后可使用以下配置选项
| 配置属性 | 说明 |
|---|---|
yarn.timeline-service.http-authentication.type |
定义用于时间线服务器(收集器/读取器)HTTP 端点的身份验证。支持的值:simple / kerberos / #AUTHENTICATION_HANDLER_CLASSNAME#。默认为 simple。 |
yarn.timeline-service.http-authentication.simple.anonymous.allowed |
指示在使用“简单”身份验证时是否允许时间线服务器进行匿名请求。默认为 true。 |
yarn.timeline-service.http-authentication.kerberos.principal |
用于时间线服务器(收集器/读取器)HTTP 端点的 Kerberos 主体。 |
yarn.timeline-service.http-authentication.kerberos.keytab |
用于时间线服务器(收集器/读取器)HTTP 端点的 Kerberos 密钥表。 |
yarn.timeline-service.principal |
时间线读取器的 Kerberos 主体。NM 主体将用于时间线收集器,因为它作为 NM 内部的辅助服务运行。 |
yarn.timeline-service.keytab |
时间线读取器的 Kerberos 密钥表。NM 密钥表将用于时间线收集器,因为它作为 NM 内部的辅助服务运行。 |
yarn.timeline-service.delegation.key.update-interval |
默认为 86400000(1 天)。 |
yarn.timeline-service.delegation.token.renew-interval |
默认为 86400000(1 天)。 |
yarn.timeline-service.delegation.token.max-lifetime |
默认为 604800000(7 天)。 |
yarn.timeline-service.read.authentication.enabled |
启用或禁用读取时间线服务 v2 数据的授权检查。默认值为 false,即禁用。 |
yarn.timeline-service.read.allowed.users |
以逗号分隔的用户列表,后跟空格,然后是逗号分隔的组列表。它将允许此用户和组列表读取数据并拒绝其他人。默认值设置为无。如果启用了授权,则此配置是必需的。 |
yarn.webapp.filter-entity-list-by-user |
默认值为 false。如果设置为 true,且 yarn.timeline-service.read.authentication.enabled 被禁用,则实体列表仅限于远程用户实体。这是用于列出 API 的 YARN 通用配置。使用此配置,TimelineReader 会使用实体所有者授权调用者 UGI。如果不匹配,则这些实体将从响应中移除。 |
要为 Timeline Service v.2 启用跨源支持 (CORS),请设置以下配置参数
在 yarn-site.xml 中,将 yarn.timeline-service.http-cross-origin.enabled 设置为 true。
在 core-site.xml 中,将 org.apache.hadoop.security.HttpCrossOriginFilterInitializer 添加到 hadoop.http.filter.initializers。
有关用于跨源支持的更多配置,请参阅 HttpAuthentication。请注意,如果 yarn.timeline-service.http-cross-origin.enabled 设置为 true,则会覆盖 hadoop.http.cross-origin.enabled。
为 Timeline Service v.2 准备存储需要执行以下几个步骤
步骤 1)设置 HBase 集群
步骤 2)启用协处理器
步骤 3)创建 Timeline Service v.2 架构
下面将详细说明每个步骤。
第一部分是设置或选择一个 Apache HBase 集群作为存储集群。受支持的 Apache HBase 版本为 1.2.6(默认)和 2.0.0-beta1。1.0.x 版本不适用于 Timeline Service v.2。默认情况下,Hadoop 版本使用 HBase 1.2.6 构建。要使用 HBase 2.0.0-beta1,请使用选项 -Dhbase.profile=2.0 从源代码构建
HBase 有不同的部署模式。请参阅 HBase 手册以了解这些模式,并选择适合您设置的模式。(http://hbase.apache.org/book.html#standalone_dist)
如果您打算为 Apache HBase 集群采用简单的部署配置文件,其中数据加载量很小,但数据需要在节点来回移动时保持持久性,则可以考虑“Standalone HBase over HDFS”部署模式。
这是独立 HBase 设置的一个有用的变体,它让所有 HBase 守护程序在同一个 JVM 内运行,但不是持久化到本地文件系统,而是持久化到 HDFS 实例。将数据写入到数据已复制的 HDFS 可确保数据在节点来回移动时保持持久性。要配置此独立变体,请编辑您的 hbase-site.xml,将 hbase.rootdir 设置为指向 HDFS 实例中的目录,但随后将 hbase.cluster.distributed 设置为 false。例如
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode.example.org:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
</configuration>
有关此模式的更多详细信息,请参阅 http://hbase.apache.org/book.html#standalone.over.hdfs 。
在 Apache HBase 集群已准备好使用后,执行以下步骤。
在此版本中,协处理器以动态方式加载(flowrun 表的表协处理器)。
将时间线服务 jar 复制到 HDFS,以便 HBase 可以从中加载它。这是模式创建器中 flowrun 表创建所必需的。默认的 HDFS 位置是 /hbase/coprocessor。例如,
hadoop fs -mkdir /hbase/coprocessor
hadoop fs -put hadoop-yarn-server-timelineservice-hbase-coprocessor-3.2.0-SNAPSHOT.jar
/hbase/coprocessor/hadoop-yarn-server-timelineservice.jar
如果您想将 jar 放置在 hdfs 上的其他位置,还存在一个名为 yarn.timeline-service.hbase.coprocessor.jar.hdfs.location 的 yarn 配置设置。例如,
<property> <name>yarn.timeline-service.hbase.coprocessor.jar.hdfs.location</name> <value>/custom/hdfs/path/jarName</value> </property>
可以在将存储时间线服务表的 hbase 集群上运行模式创建。模式创建器工具需要 timelineservice-hbase 和 hbase-server jar。因此,在模式创建期间,您需要确保 hbase 类路径包含 yarn-timelineservice-hbase jar。
在 hbase 集群上,您可以从 hdfs 获取它,因为我们在上面的步骤中已将其放置在协处理器中。
hadoop fs -get /hbase/coprocessor/hadoop-yarn-server-timelineservice-hbase-client-${project.version}.jar <local-dir>/.
hadoop fs -get /hbase/coprocessor/hadoop-yarn-server-timelineservice-${project.version}.jar <local-dir>/.
hadoop fs -get /hbase/coprocessor/hadoop-yarn-server-timelineservice-hbase-common-${project.version}.jar <local-dir>/.
接下来,将其添加到 hbase 类路径中,如下所示
export HBASE_CLASSPATH=$HBASE_CLASSPATH:/home/yarn/hadoop-current/share/hadoop/yarn/timelineservice/hadoop-yarn-server-timelineservice-hbase-client-${project.version}.jar
export HBASE_CLASSPATH=$HBASE_CLASSPATH:/home/yarn/hadoop-current/share/hadoop/yarn/timelineservice/hadoop-yarn-server-timelineservice-${project.version}.jar
export HBASE_CLASSPATH=$HBASE_CLASSPATH:/home/yarn/hadoop-current/share/hadoop/yarn/timelineservice/hadoop-yarn-server-timelineservice-hbase-common-${project.version}.jar
最后,运行模式创建器工具以创建必要的表
bin/hbase org.apache.hadoop.yarn.server.timelineservice.storage.TimelineSchemaCreator -create
TimelineSchemaCreator 工具支持一些选项,这些选项在您进行测试时会特别方便。例如,您可以使用 -skipExistingTable(简称 -s)跳过现有表,并继续创建其他表,而不是使模式创建失败。默认情况下,表将具有“prod.”模式前缀。如果没有提供选项或“help”(简称“h”),则会打印命令用法。选项(-entityTableName、-appToflowTableName、-applicationTableName、-subApplicationTableName)将有助于覆盖默认表名。在使用自定义表名时,必须在 yarn.timeline-service.hbase.configuration.file 中配置的 hbase-site.xml 中设置具有自定义表名的以下对应配置。
yarn.timeline-service.app-flow.table.name yarn.timeline-service.entity.table.name yarn.timeline-service.application.table.name yarn.timeline-service.subapplication.table.name yarn.timeline-service.flowactivity.table.name yarn.timeline-service.flowrun.table.name yarn.timeline-service.domain.table.name
以下是启动时间线服务 v.2 的基本配置
<property> <name>yarn.timeline-service.version</name> <value>2.0f</value> </property> <property> <name>yarn.timeline-service.enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle,timeline_collector</value> </property> <property> <name>yarn.nodemanager.aux-services.timeline_collector.class</name> <value>org.apache.hadoop.yarn.server.timelineservice.collector.PerNodeTimelineCollectorsAuxService</value> </property> <property> <description>The setting that controls whether yarn system metrics is published on the Timeline service or not by RM And NM.</description> <name>yarn.system-metrics-publisher.enabled</name> <value>true</value> </property>
如果使用辅助服务清单而不是通过配置设置辅助服务,请确保清单服务数组包括时间线收集器服务,如下所示
{
"services": [
{
"name": "timeline_collector",
"configuration": {
"properties": {
"class.name": "org.apache.hadoop.yarn.server.timelineservice.collector.PerNodeTimelineCollectorsAuxService"
}
}
}
]
}
此外,如果您使用多个集群在同一 Apache HBase 存储中存储数据,则可能希望将 YARN 集群名称设置为一个相当唯一的名称
<property> <name>yarn.resourcemanager.cluster-id</name> <value>my_research_test_cluster</value> </property>
此外,将 hbase-site.xml 配置文件添加到客户端 Hadoop 集群配置,以便它可以将数据写入您正在使用的 Apache HBase 集群,或将 yarn.timeline-service.hbase.configuration.file 设置为指向 hbase-site.xml 的文件 URL,以实现相同目的。例如
<property> <description> Optional URL to an hbase-site.xml configuration file to be used to connect to the timeline-service hbase cluster. If empty or not specified, then the HBase configuration will be loaded from the classpath. When specified the values in the specified configuration file will override those from the ones that are present on the classpath. </description> <name>yarn.timeline-service.hbase.configuration.file</name> <value>file:/etc/hbase/hbase-ats-dc1/hbase-site.xml</value> </property>
要同时配置时间线服务 1.5 和 v.2,请添加以下属性
<property> <name>yarn.timeline-service.versions</name> <value>1.5f,2.0f</value> </property>
如果未配置上述内容,则它将默认为 yarn.timeline-service.version 中设置的版本
重新启动资源管理器以及节点管理器以获取新配置。收集器在资源管理器和节点管理器中以嵌入方式启动。
时间线服务读取器是一个单独的 YARN 守护进程,可以使用以下语法启动
$ yarn-daemon.sh start timelinereader
要将 MapReduce 框架数据写入时间线服务 v.2,请在 mapred-site.xml 中启用以下配置
<property> <name>mapreduce.job.emit-timeline-data</name> <value>true</value> </property>
如果您当前正在运行时间线服务 v2 alpha1 版本,我们建议您执行以下操作
清除表中的现有数据(截断表),因为 AppToFlow 的行键已更改。
协处理器现在是 GA 中的动态加载表级协处理器。我们建议删除表,将 hdfs 上的协处理器 jar 替换为 GA jar,重新启动区域服务器并重新创建 flowrun 表。
本部分适用于希望与时间线服务 v.2 集成的 YARN 应用程序开发人员。
开发人员需要使用 TimelineV2Client API 将每个框架的数据发布到时间线服务 v.2。v.2 的实体/对象 API 与 v.1 不同,因为对象模型已发生重大更改。v.2 时间线实体类是 org.apache.hadoop.yarn.api.records.timelineservice.TimelineEntity。
时间线服务 v.2 putEntities 方法有 2 种类型:putEntities 和 putEntitiesAsync。前者是一个阻塞操作,必须用于写入更关键的数据(例如生命周期事件)。后者是一个非阻塞操作。请注意,两者都没有返回值。
创建 TimelineV2Client 涉及将应用程序 ID 传递给静态方法 TimelineV2Client.createTimelineClient。
例如
// Create and start the Timeline client v.2
TimelineV2Client timelineClient =
TimelineV2Client.createTimelineClient(appId);
timelineClient.init(conf);
timelineClient.start();
try {
TimelineEntity myEntity = new TimelineEntity();
myEntity.setType("MY_APPLICATION");
myEntity.setId("MyApp1");
// Compose other entity info
// Blocking write
timelineClient.putEntities(myEntity);
TimelineEntity myEntity2 = new TimelineEntity();
// Compose other info
// Non-blocking write
timelineClient.putEntitiesAsync(myEntity2);
} catch (IOException | YarnException e) {
// Handle the exception
} finally {
// Stop the Timeline client
timelineClient.stop();
}
如上所述,您需要指定 YARN 应用程序 ID 才能写入时间线服务 v.2。请注意,目前您需要在集群中才能写入时间线服务。例如,应用程序主控或容器中的代码可以写入时间线服务,而集群外 MapReduce 作业提交方则不能。
创建时间线 v2 客户端后,用户还需要设置时间线收集器信息,其中包含收集器地址和收集器令牌(仅在安全模式下)以供应用程序使用。如果使用 AMRMClient,则通过调用 AMRMClient#registerTimelineV2Client 注册时间线客户端就足够了。
amRMClient.registerTimelineV2Client(timelineClient);
否则,需要从 AM 分配响应中检索地址,并需要明确在时间线客户端中设置。
timelineClient.setTimelineCollectorInfo(response.getCollectorInfo());
您可以像以前版本一样创建和发布您自己的实体、事件和指标。
TimelineEntity 对象具有以下字段来保存时间线数据
请注意,在发布时间线指标时,可以通过 TimelineMetric#setRealtimeAggregationOp() 方法选择如何聚合每个指标。此处“聚合”一词意味着对一组实体应用一个 TimelineMetricOperation。Timeline 服务 v2 提供内置的应用程序级别聚合,这意味着聚合一个 YARN 应用程序中不同时间线实体的指标。目前,TimelineMetricOperation 中支持两种操作
MAX:获取所有 TimelineMetric 对象中的最大值。SUM:获取所有 TimelineMetric 对象的总和。默认情况下,NOP 操作意味着不执行任何实时聚合操作。
应用程序框架必须尽可能设置“流上下文”,以便利用 Timeline Service v.2 提供的流支持。流上下文包括以下内容
如果未指定流上下文,则会为这些属性提供默认值
您可以通过 YARN 应用程序标签提供流上下文
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
// set the flow context as YARN application tags
Set<String> tags = new HashSet<>();
tags.add(TimelineUtils.generateFlowNameTag("distributed grep"));
tags.add(Timelineutils.generateFlowVersionTag("3df8b0d6100530080d2e0decf9e528e57c42a90a"));
tags.add(TimelineUtils.generateFlowRunIdTag(System.currentTimeMillis()));
appContext.setApplicationTags(tags);
注意:资源管理器在存储 YARN 应用程序标签之前会将其转换为小写。因此,在 REST API 查询中使用流名称和流版本之前,应将其转换为小写。
目前仅通过 REST API 支持查询 Timeline Service v.2;YARN 库中未实现 API 客户端。
v.2 REST API 在 Timeline Service Web 服务上的路径 /ws/v2/timeline/ 下实现。
以下是 API 的非正式说明。
GET /ws/v2/timeline/
返回描述服务实例和版本信息的 JSON 对象。
{
"About":"Timeline Reader API",
"timeline-service-version":"3.0.0-alpha1-SNAPSHOT",
"timeline-service-build-version":"3.0.0-alpha1-SNAPSHOT from fb0acd08e6f0b030d82eeb7cbfa5404376313e60 by sjlee source checksum be6cba0e42417d53be16459e1685e7",
"timeline-service-version-built-on":"2016-04-11T23:15Z",
"hadoop-version":"3.0.0-alpha1-SNAPSHOT",
"hadoop-build-version":"3.0.0-alpha1-SNAPSHOT from fb0acd08e6f0b030d82eeb7cbfa5404376313e60 by sjlee source checksum ee968fd0aedcc7384230ee3ca216e790",
"hadoop-version-built-on":"2016-04-11T23:14Z"
}
以下显示了 REST API 上支持的查询。
使用查询流 API,您可以检索最近运行过的活动流列表。如果使用不带群集名称的 REST 端点,则采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的群集。如果没有流与谓词匹配,则将返回一个空列表。
GET /ws/v2/timeline/clusters/{cluster name}/flows/
or
GET /ws/v2/timeline/flows/
limit - 如果指定,则定义要返回的流数。limit 的最大可能值为 Long 的最大值。如果未指定或值为小于 0,则 limit 将被视为 100。daterange - 如果指定,则给出为 “[startdate]-[enddate]”(即以 “-” 分隔的开始日期和结束日期)或单个日期。日期以 yyyyMMdd 格式解释,并假定为 UTC。如果指定了单个日期,则返回该日期活动的所有流。如果同时给出了 startdate 和 enddate,则返回在开始日期和结束日期之间活动的所有流。如果仅给出了 startdate,则返回在 startdate 及之后活动的所有流。如果仅给出了 enddate,则返回在 enddate 及之前活动的所有流。fromid - 如果指定,则从给定的 fromid 检索下一组流。检索的实体集包含指定的 fromid。fromid 应取自先前发送的流实体响应中与 FROM_ID 信息键关联的值。[
{
"metrics": [],
"events": [],
"id": "test-cluster/1460419200000/sjlee@ds-date",
"type": "YARN_FLOW_ACTIVITY",
"createdtime": 0,
"flowruns": [
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420305659",
"type": "YARN_FLOW_RUN",
"createdtime": 0,
"info": {
"SYSTEM_INFO_FLOW_VERSION": "1",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420305659,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
},
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420587974",
"type": "YARN_FLOW_RUN",
"createdtime": 0,
"info": {
"SYSTEM_INFO_FLOW_VERSION": "1",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420587974,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
}
],
"info": {
"SYSTEM_INFO_CLUSTER": "test-cluster",
"UID": "test-cluster!sjlee!ds-date",
"FROM_ID": "test-cluster!1460419200000!sjlee!ds-date",
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_DATE": 1460419200000,
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
}
]
使用查询流运行 API,您可以进一步深入了解以获取给定流的运行(特定实例)。这将返回属于给定流的最新运行。如果使用不带群集名称的 REST 端点,则采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的群集。如果没有流运行与谓词匹配,则将返回一个空列表。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/runs/
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/runs/
limit - 如果指定,则定义要返回的流数。limit 的最大可能值为 Long 的最大值。如果未指定或值为小于 0,则 limit 将被视为 100。createdtimestart - 如果指定,则仅返回在此时间戳之后启动的流运行。createdtimeend - 如果指定,则仅返回在此时间戳之前启动的流运行。metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。fields - 指定要检索哪些字段。对于查询流运行,只有 ALL 或 METRICS 是有效的字段。其他字段将导致 HTTP 400(错误请求)响应。如果未指定,则在响应中,将返回 id、type、createdtime 和 info 字段。fromid - 如果指定,则从给定的 fromid 中检索下一组流运行实体。检索的实体集包含指定的 fromid。fromid 应取自先前发送的流实体响应中与 FROM_ID 信息键关联的值。[
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420587974",
"type": "YARN_FLOW_RUN",
"createdtime": 1460420587974,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460420587974",
"FROM_ID": "test-cluster!sjlee!ds-date!1460420587974",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420587974,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_FLOW_RUN_END_TIME": 1460420595198,
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
},
{
"metrics": [],
"events": [],
"id": "sjlee@ds-date/1460420305659",
"type": "YARN_FLOW_RUN",
"createdtime": 1460420305659,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460420305659",
"FROM_ID": "test-cluster!sjlee!ds-date!1460420305659",
"SYSTEM_INFO_FLOW_RUN_ID": 1460420305659,
"SYSTEM_INFO_FLOW_NAME": "ds-date",
"SYSTEM_INFO_FLOW_RUN_END_TIME": 1460420311966,
"SYSTEM_INFO_USER": "sjlee"
},
"isrelatedto": {},
"relatesto": {}
}
]
使用此 API,您可以查询由集群、用户、流名称和运行 ID 标识的特定流运行。如果使用不带集群名称的 REST 端点,则采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的集群。在查询单个流运行时,默认情况下返回指标。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/runs/{run id}
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/runs/{run id}
metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:{
"metrics": [
{
"type": "SINGLE_VALUE",
"id": "org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter:BYTES_READ",
"aggregationOp": "NOP",
"values": {
"1465246377261": 118
}
},
{
"type": "SINGLE_VALUE",
"id": "org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter:BYTES_WRITTEN",
"aggregationOp": "NOP",
"values": {
"1465246377261": 97
}
}
],
"events": [],
"id": "varun@QuasiMonteCarlo/1465246348599",
"type": "YARN_FLOW_RUN",
"createdtime": 1465246348599,
"isrelatedto": {},
"info": {
"UID":"yarn-cluster!varun!QuasiMonteCarlo!1465246348599",
"FROM_ID":"yarn-cluster!varun!QuasiMonteCarlo!1465246348599",
"SYSTEM_INFO_FLOW_RUN_END_TIME":1465246378051,
"SYSTEM_INFO_FLOW_NAME":"QuasiMonteCarlo",
"SYSTEM_INFO_USER":"varun",
"SYSTEM_INFO_FLOW_RUN_ID":1465246348599
},
"relatesto": {}
}
使用此 API,您可以查询属于特定流的所有 YARN 应用程序。如果使用不带集群名称的 REST 端点,则采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的集群。如果匹配的应用程序数量超过限制,则将返回最多达到限制的最新的应用程序。如果没有任何应用程序与谓词匹配,则将返回一个空列表。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/apps
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/apps
limit - 如果指定,则定义要返回的应用程序数。limit 的最大可能值为 Long 的最大值。如果未指定或值为小于 0,则 limit 将被视为 100。createdtimestart - 如果指定,则仅返回在此时间戳之后创建的应用程序。createdtimeend - 如果指定,则仅返回在此时间戳之前创建的应用程序。relatesto - 如果指定,则匹配的应用程序必须与与实体类型关联的给定实体相关或不相关。relatesto 表示为以下形式的表达式isrelatedto - 如果指定,则匹配的应用程序必须与与实体类型关联的给定实体相关或不相关。isrelatedto 的表示形式与 relatesto 相同。infofilters - 如果指定,则匹配的应用程序必须与给定的信息键完全匹配,并且必须等于或不等于给定的值。信息键是一个字符串,但值可以是任何对象。infofilters 表示为以下形式的表达式conffilters - 如果指定,则匹配的应用程序必须与给定的配置名称完全匹配,并且必须等于或不等于给定的配置值。配置名称和值都必须是字符串。conffilters 以与 infofilters 相同的形式表示。metricfilters - 如果指定,则匹配的应用程序必须与给定的指标完全匹配,并且必须满足与指标值指定的关系。指标 ID 必须是一个字符串,指标值必须是一个整数。metricfilters 表示为以下形式的表达式eventfilters - 如果指定,则匹配的应用程序必须根据表达式包含或不包含给定的事件。eventfilters 表示为以下形式的表达式metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。confstoretrieve - 如果指定,则定义要检索的配置或不检索的配置,并在响应中发回。confstoretrieve 可以是以下形式的表达式CONFIGS,都将检索配置。请注意,URL 不安全的字符(如空格)必须进行适当编码。fields - 指定要检索的字段。fields 的可能值为 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定了 ALL,则将检索所有字段。可以将多个字段指定为以逗号分隔的列表。如果未指定 fields,则在响应中,将返回信息字段中的应用 ID、类型(相当于 YARN_APPLICATION)、应用创建时间和 UID。metricslimit - 如果指定,定义要返回的指标数。仅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 时考虑。否则忽略。metricslimit 的最大可能值为 Integer 的最大值。如果未指定或值小于 1,并且必须检索指标,则 metricslimit 将被视为 1,即返回指标的最新单个值。metricstimestart - 如果指定,则返回此时间戳之后实体的指标。metricstimeend - 如果指定,则返回此时间戳之前实体的指标。fromid - 如果指定,从给定的 fromid 检索下一组应用程序实体。检索的实体集包含指定的 fromid。fromid 应取自先前发送的流实体响应中与 FROM_ID 信息键关联的值。[
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION",
"id": "application_1465246237936_0001",
"createdtime": 1465246348599,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001"
"FROM_ID": "yarn-cluster!varun!QuasiMonteCarlo!1465246348599!application_1465246237936_0001",
},
"relatesto": { }
},
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION",
"id": "application_1464983628730_0005",
"createdtime": 1465033881959,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1464983628730_0005"
"FROM_ID": "yarn-cluster!varun!QuasiMonteCarlo!1465246348599!application_1464983628730_0005",
},
"relatesto": { }
}
]
使用此 API,您可以查询属于特定流运行的所有 YARN 应用程序。如果使用不带群集名称的 REST 端点,则会采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的群集。如果匹配的应用程序数量超过限制,则将返回最新的应用程序(最多达到限制)。如果没有任何应用程序与谓词匹配,则将返回一个空列表。
GET /ws/v2/timeline/clusters/{cluster name}/users/{user name}/flows/{flow name}/runs/{run id}/apps
or
GET /ws/v2/timeline/users/{user name}/flows/{flow name}/runs/{run id}/apps/
limit - 如果指定,则定义要返回的应用程序数。limit 的最大可能值为 Long 的最大值。如果未指定或值为小于 0,则 limit 将被视为 100。createdtimestart - 如果指定,则仅返回在此时间戳之后创建的应用程序。createdtimeend - 如果指定,则仅返回在此时间戳之前创建的应用程序。relatesto - 如果指定,则匹配的应用程序必须与与实体类型关联的给定实体相关或不相关。relatesto 表示为以下形式的表达式isrelatedto - 如果指定,则匹配的应用程序必须与与实体类型关联的给定实体相关或不相关。isrelatedto 的表示形式与 relatesto 相同。infofilters - 如果指定,则匹配的应用程序必须与给定的信息键完全匹配,并且必须等于或不等于给定的值。信息键是一个字符串,但值可以是任何对象。infofilters 表示为以下形式的表达式conffilters - 如果指定,则匹配的应用程序必须与给定的配置名称完全匹配,并且必须等于或不等于给定的配置值。配置名称和值都必须是字符串。conffilters 以与 infofilters 相同的形式表示。metricfilters - 如果指定,则匹配的应用程序必须与给定的指标完全匹配,并且必须满足与指标值指定的关系。指标 ID 必须是一个字符串,指标值必须是一个整数。metricfilters 表示为以下形式的表达式eventfilters - 如果指定,则匹配的应用程序必须根据表达式包含或不包含给定的事件。eventfilters 表示为以下形式的表达式metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。confstoretrieve - 如果指定,则定义要检索的配置或不检索的配置,并在响应中发回。confstoretrieve 可以是以下形式的表达式CONFIGS,都将检索配置。请注意,URL 不安全的字符(如空格)必须进行适当编码。fields - 指定要检索的字段。fields 的可能值为 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定了 ALL,则将检索所有字段。可以将多个字段指定为以逗号分隔的列表。如果未指定 fields,则在响应中,将返回信息字段中的应用 ID、类型(相当于 YARN_APPLICATION)、应用创建时间和 UID。metricslimit - 如果指定,定义要返回的指标数。仅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 时考虑。否则忽略。metricslimit 的最大可能值为 Integer 的最大值。如果未指定或值小于 1,并且必须检索指标,则 metricslimit 将被视为 1,即返回指标的最新单个值。metricstimestart - 如果指定,则返回此时间戳之后实体的指标。metricstimeend - 如果指定,则返回此时间戳之前实体的指标。fromid - 如果指定,从给定的 fromid 检索下一组应用程序实体。检索的实体集包含指定的 fromid。fromid 应取自先前发送的流实体响应中与 FROM_ID 信息键关联的值。[
{
"metrics": [],
"events": [],
"id": "application_1460419579913_0002",
"type": "YARN_APPLICATION",
"createdtime": 1460419580171,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460419580171!application_1460419579913_0002"
"FROM_ID": "test-cluster!sjlee!ds-date!1460419580171!application_1460419579913_0002",
},
"configs": {},
"isrelatedto": {},
"relatesto": {}
}
]
使用此 API,您可以通过群集和应用程序 ID 查询单个 YARN 应用程序。如果使用不带群集名称的 REST 端点,则会采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的群集。流上下文信息(即用户、流名称和运行 ID)不是必需的,但如果在查询参数中指定,可以避免需要基于群集和应用程序 ID 获取流上下文信息的额外操作。
GET /ws/v2/timeline/clusters/{cluster name}/apps/{app id}
or
GET /ws/v2/timeline/apps/{app id}
userid - 如果指定,则仅返回属于此用户的应用程序。此查询参数必须与 flowname 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则我们必须在执行查询时基于群集和 appid 获取流上下文信息。flowname - 仅返回属于此流名称的应用程序。此查询参数必须与 userid 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则我们必须在执行查询时基于群集和 appid 获取流上下文信息。flowrunid - 仅返回属于此流程运行 ID 的应用程序。此查询参数必须与 userid 和 flowname 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们必须根据群集和 appid 获取流程上下文信息。metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。confstoretrieve - 如果指定,则定义要检索的配置或不检索的配置,并在响应中发回。confstoretrieve 可以是以下形式的表达式CONFIGS,都将检索配置。请注意,URL 不安全的字符(如空格)必须进行适当编码。fields - 指定要检索的字段。fields 的可能值为 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定了 ALL,则将检索所有字段。可以将多个字段指定为以逗号分隔的列表。如果未指定 fields,则在响应中,将返回信息字段中的应用 ID、类型(相当于 YARN_APPLICATION)、应用创建时间和 UID。metricslimit - 如果指定,定义要返回的指标数。仅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 时考虑。否则忽略。metricslimit 的最大可能值为 Integer 的最大值。如果未指定或值小于 1,并且必须检索指标,则 metricslimit 将被视为 1,即返回指标的最新单个值。metricstimestart - 如果指定,则返回此时间戳之后实体的指标。metricstimeend - 如果指定,则返回此时间戳之前实体的指标。{
"metrics": [],
"events": [],
"id": "application_1460419579913_0002",
"type": "YARN_APPLICATION",
"createdtime": 1460419580171,
"info": {
"UID": "test-cluster!sjlee!ds-date!1460419580171!application_1460419579913_0002"
},
"configs": {},
"isrelatedto": {},
"relatesto": {}
}
利用此 API,您可以查询由群集 ID、应用程序 ID 和每个框架实体类型标识的通用实体。如果使用不带群集名称的 REST 端点,则将采用 yarn-site.xml 中配置的 yarn.resourcemanager.cluster-id 指定的群集。流程上下文信息(即用户、流程名称和运行 ID)不是必需的,但如果在查询参数中指定,则可以避免执行其他操作以根据群集和 app id 获取流程上下文信息。如果匹配实体的数量超过限制,则将返回最多限制数量的最新实体。此端点可用于查询容器、应用程序尝试或客户端放入后端的任何其他通用实体。例如,我们可以通过将实体类型指定为 YARN_CONTAINER 来查询容器,通过将实体类型指定为 YARN_APPLICATION_ATTEMPT 来查询应用程序尝试。如果没有实体与谓词匹配,则将返回一个空列表。
GET /ws/v2/timeline/clusters/{cluster name}/apps/{app id}/entities/{entity type}
or
GET /ws/v2/timeline/apps/{app id}/entities/{entity type}
userid - 如果指定,则仅返回属于此用户的实体。此查询参数必须与 flowname 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们必须根据群集和 appid 获取流程上下文信息。flowname - 如果指定,则仅返回属于此流程名称的实体。此查询参数必须与 userid 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们必须根据群集和 appid 获取流程上下文信息。flowrunid - 如果指定,则仅返回属于此流程运行 ID 的实体。此查询参数必须与 userid 和 flowname 查询参数一起指定,否则将被忽略。如果没有指定 userid、flowname 和 flowrunid,则在执行查询时,我们必须基于集群和 appid 获取流程上下文信息。limit - 如果指定,则定义要返回的实体数量。limit 的最大可能值为 Long 的最大值。如果未指定或值为小于 0,则 limit 将被视为 100。createdtimestart - 如果指定,则仅返回在此时间戳之后创建的实体。createdtimeend - 如果指定,则仅返回在此时间戳之前创建的实体。relatesto - 如果指定,则匹配的实体必须与关联到实体类型的给定实体相关联或不相关。relatesto 表示为以下形式的表达式isrelatedto - 如果指定,则匹配的实体必须与关联到实体类型的给定实体相关联或不相关。isrelatedto 的表示形式与 relatesto 相同。infofilters - 如果指定,则匹配的实体必须与给定的信息键完全匹配,并且必须等于或不等于给定的值。信息键是一个字符串,但值可以是任何对象。infofilters 表示为以下形式的表达式conffilters - 如果指定,则匹配的实体必须与给定的配置名称完全匹配,并且必须等于或不等于给定的配置值。配置名称和值都必须是字符串。conffilters 的表示形式与 infofilters 相同。metricfilters - 如果指定,则匹配的实体必须与给定的指标完全匹配,并且必须满足与指标值指定的关系。指标 ID 必须是一个字符串,指标值必须是一个整数。metricfilters 表示为以下形式的表达式eventfilters - 如果指定,则匹配的实体必须根据表达式包含或不包含给定事件。eventfilters 表示为以下形式的表达式metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。confstoretrieve - 如果指定,则定义要检索的配置或不检索的配置,并在响应中发回。confstoretrieve 可以是以下形式的表达式CONFIGS,都将检索配置。请注意,URL 不安全的字符(如空格)必须进行适当编码。fields - 指定要检索的字段。字段的可能值为 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定 ALL,将检索所有字段。多个字段可以作为逗号分隔的列表指定。如果未指定字段,作为响应,将返回信息字段中的实体 ID、实体类型、创建时间和 UID。metricslimit - 如果指定,定义要返回的指标数。仅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 时考虑。否则忽略。metricslimit 的最大可能值为 Integer 的最大值。如果未指定或值小于 1,并且必须检索指标,则 metricslimit 将被视为 1,即返回指标的最新单个值。metricstimestart - 如果指定,则返回此时间戳之后实体的指标。metricstimeend - 如果指定,则返回此时间戳之前实体的指标。fromid - 如果指定,从给定的 fromid 检索下一组通用实体。检索的实体集包含指定的 fromid。fromid 应取自先前发送的流实体响应中与 FROM_ID 信息键关联的值。[
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION_ATTEMPT",
"id": "appattempt_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!appattempt_1465246237936_0001_000001"
"FROM_ID": "yarn-cluster!sjlee!ds-date!1460419580171!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000001"
},
"relatesto": { }
},
{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION_ATTEMPT",
"id": "appattempt_1465246237936_0001_000002",
"createdtime": 1465246359045,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!appattempt_1465246237936_0001_000002"
"FROM_ID": "yarn-cluster!sjlee!ds-date!1460419580171!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000002"
},
"relatesto": { }
}
]
通过此 API,您可以按由群集 ID、doAsUser 和实体类型标识的用户查询通用实体。如果使用不带群集名称的 REST 端点,则将采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的群集。如果匹配的实体数量超过限制,将返回最多达到该限制的最新的实体。此端点可用于查询客户端放入后端的通用实体。例如,我们可以通过将实体类型指定为 TEZ_DAG_ID 来查询用户实体。如果没有任何实体与谓词匹配,将返回一个空列表。注意:截至今日,我们只能查询使用与应用程序所有者不同的 doAsUser 发布的那些实体。
GET /ws/v2/timeline/clusters/{cluster name}/users/{userid}/entities/{entitytype}
or
GET /ws/v2/timeline/users/{userid}/entities/{entitytype}
limit - 如果指定,则定义要返回的实体数量。limit 的最大可能值为 Long 的最大值。如果未指定或值为小于 0,则 limit 将被视为 100。createdtimestart - 如果指定,则仅返回在此时间戳之后创建的实体。createdtimeend - 如果指定,则仅返回在此时间戳之前创建的实体。relatesto - 如果指定,则匹配的实体必须与关联到实体类型的给定实体相关联或不相关。relatesto 表示为以下形式的表达式isrelatedto - 如果指定,则匹配的实体必须与关联到实体类型的给定实体相关联或不相关。isrelatedto 的表示形式与 relatesto 相同。infofilters - 如果指定,则匹配的实体必须与给定的信息键完全匹配,并且必须等于或不等于给定的值。信息键是一个字符串,但值可以是任何对象。infofilters 表示为以下形式的表达式conffilters - 如果指定,则匹配的实体必须与给定的配置名称完全匹配,并且必须等于或不等于给定的配置值。配置名称和值都必须是字符串。conffilters 的表示形式与 infofilters 相同。metricfilters - 如果指定,则匹配的实体必须与给定的指标完全匹配,并且必须满足与指标值指定的关系。指标 ID 必须是一个字符串,指标值必须是一个整数。metricfilters 表示为以下形式的表达式eventfilters - 如果指定,则匹配的实体必须根据表达式包含或不包含给定事件。eventfilters 表示为以下形式的表达式metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。confstoretrieve - 如果指定,则定义要检索的配置或不检索的配置,并在响应中发回。confstoretrieve 可以是以下形式的表达式CONFIGS,都将检索配置。请注意,URL 不安全的字符(如空格)必须进行适当编码。fields - 指定要检索的字段。字段的可能值为 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定 ALL,将检索所有字段。多个字段可以作为逗号分隔的列表指定。如果未指定字段,作为响应,将返回信息字段中的实体 ID、实体类型、创建时间和 UID。metricslimit - 如果指定,定义要返回的指标数。仅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 时考虑。否则忽略。metricslimit 的最大可能值为 Integer 的最大值。如果未指定或值小于 1,并且必须检索指标,则 metricslimit 将被视为 1,即返回指标的最新单个值。metricstimestart - 如果指定,则返回此时间戳之后实体的指标。metricstimeend - 如果指定,则返回此时间戳之前实体的指标。fromid - 如果指定,从给定的 fromid 检索下一组通用实体。检索的实体集包含指定的 fromid。fromid 应取自先前发送的流实体响应中与 FROM_ID 信息键关联的值。[
{
"metrics": [ ],
"events": [ ],
"type": "TEZ_DAG_ID",
"id": "dag_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!sjlee!TEZ_DAG_ID!0!dag_1465246237936_0001_000001"
"FROM_ID": "sjlee!yarn-cluster!TEZ_DAG_ID!0!dag_1465246237936_0001_000001"
},
"relatesto": { }
},
{
"metrics": [ ],
"events": [ ],
"type": "TEZ_DAG_ID",
"id": "dag_1465246237936_0001_000002",
"createdtime": 1465246359045,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!sjlee!TEZ_DAG_ID!0!dag_1465246237936_0001_000002!userX"
"FROM_ID": "sjlee!yarn-cluster!TEZ_DAG_ID!0!dag_1465246237936_0001_000002!userX"
},
"relatesto": { }
}
]
通过此 API,您可以按群集 ID、应用程序 ID、每个框架的实体类型和实体 ID 查询特定的通用实体。如果使用不带群集名称的 REST 端点,则将采用 yarn-site.xml 中配置 yarn.resourcemanager.cluster-id 指定的群集。流上下文信息(即用户、流名称和运行 ID)不是必需的,但如果在查询参数中指定,则可以避免需要执行另一项操作来基于群集和应用程序 ID 获取流上下文信息。此端点可用于查询单个容器、应用程序尝试或客户端放入后端的任何其他通用实体。例如,我们可以通过将实体类型指定为 YARN_CONTAINER 并将实体 ID 指定为容器 ID 来查询特定的 YARN 容器。同样,可以通过将实体类型指定为 YARN_APPLICATION_ATTEMPT 且实体 ID 为应用程序尝试 ID 来查询应用程序尝试。
GET /ws/v2/timeline/clusters/{cluster name}/apps/{app id}/entities/{entity type}/{entity id}
or
GET /ws/v2/timeline/apps/{app id}/entities/{entity type}/{entity id}
userid - 如果指定,则实体必须属于此用户。此查询参数必须与 flowname 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们将不得不基于集群和 appid 获取流上下文信息。flowname - 如果指定,则实体必须属于此流名称。此查询参数必须与 userid 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们将不得不基于集群和 appid 获取流上下文信息。flowrunid - 如果指定,则实体必须属于此流运行 ID。此查询参数必须与 userid 和 flowname 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们将不得不基于集群和 appid 获取流上下文信息。metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。confstoretrieve - 如果指定,则定义要检索的配置或不检索的配置,并在响应中发回。confstoretrieve 可以是以下形式的表达式CONFIGS,都将检索配置。请注意,URL 不安全的字符(如空格)必须进行适当编码。fields - 指定要检索的字段。字段的可能值为 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定 ALL,将检索所有字段。多个字段可以作为逗号分隔的列表指定。如果未指定字段,作为响应,将返回信息字段中的实体 ID、实体类型、创建时间和 UID。metricslimit - 如果指定,定义要返回的指标数。仅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 时考虑。否则忽略。metricslimit 的最大可能值为 Integer 的最大值。如果未指定或值小于 1,并且必须检索指标,则 metricslimit 将被视为 1,即返回指标的最新单个值。metricstimestart - 如果指定,则返回此时间戳之后实体的指标。metricstimeend - 如果指定,则返回此时间戳之前实体的指标。entityidprefix 定义要获取的实体的 ID 前缀。如果指定,则实体检索将更快。{
"metrics": [ ],
"events": [ ],
"type": "YARN_APPLICATION_ATTEMPT",
"id": "appattempt_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000001"
"FROM_ID": "yarn-cluster!sjlee!ds-date!1460419580171!application_1465246237936_0001!YARN_APPLICATION_ATTEMPT!0!appattempt_1465246237936_0001_000001"
},
"relatesto": { }
}
使用此 API,您可以按由集群 ID、doAsUser 和实体类型和实体 ID 标识的用户查询通用实体。如果使用不带集群名称的 REST 端点,则会采用在 yarn-site.xml 中的配置 yarn.resourcemanager.cluster-id 指定的集群。如果匹配的实体数超过限制,则将返回多达限制的最新的实体。此端点可用于查询客户端放入后端的通用实体。例如,我们可以通过将实体类型指定为 TEZ_DAG_ID 来查询用户实体。如果没有任何实体与谓词匹配,则将返回一个空列表。注意:截至今日,我们只能查询使用与应用程序所有者不同的 doAsUser 发布的实体。
GET /ws/v2/timeline/clusters/{cluster name}/users/{userid}/entities/{entitytype}/{entityid}
or
GET /ws/v2/timeline/users/{userid}/entities/{entitytype}/{entityid}
metricstoretrieve - 如果指定,则定义要检索或不检索哪些指标以及在响应中发送回哪些指标。metricstoretrieve 可以是以下形式的表达式:METRICS,都将检索指标。请注意,URL 不安全的字符(例如空格)必须进行适当编码。confstoretrieve - 如果指定,则定义要检索的配置或不检索的配置,并在响应中发回。confstoretrieve 可以是以下形式的表达式CONFIGS,都将检索配置。请注意,URL 不安全的字符(如空格)必须进行适当编码。fields - 指定要检索的字段。字段的可能值为 EVENTS、INFO、CONFIGS、METRICS、RELATES_TO、IS_RELATED_TO 和 ALL。如果指定 ALL,将检索所有字段。多个字段可以作为逗号分隔的列表指定。如果未指定字段,作为响应,将返回信息字段中的实体 ID、实体类型、创建时间和 UID。metricslimit - 如果指定,定义要返回的指标数。仅在 fields 包含 METRICS/ALL 或指定 metricstoretrieve 时考虑。否则忽略。metricslimit 的最大可能值为 Integer 的最大值。如果未指定或值小于 1,并且必须检索指标,则 metricslimit 将被视为 1,即返回指标的最新单个值。metricstimestart - 如果指定,则返回此时间戳之后实体的指标。metricstimeend - 如果指定,则返回此时间戳之前实体的指标。fromid - 如果指定,从给定的 fromid 检索下一组通用实体。检索的实体集包含指定的 fromid。fromid 应取自先前发送的流实体响应中与 FROM_ID 信息键关联的值。[
{
"metrics": [ ],
"events": [ ],
"type": "TEZ_DAG_ID",
"id": "dag_1465246237936_0001_000001",
"createdtime": 1465246358873,
"isrelatedto": { },
"configs": { },
"info": {
"UID": "yarn-cluster!sjlee!TEZ_DAG_ID!0!dag_1465246237936_0001_000001!userX"
"FROM_ID": "sjlee!yarn-cluster!TEZ_DAG_ID!0!dag_1465246237936_0001_000001!userX"
},
"relatesto": { }
}
]
借助此 API,您可以查询给定应用 ID 的可用实体类型集合。如果使用了不带集群名称的 REST 端点,则将采用 yarn-site.xml 中 yarn.resourcemanager.cluster-id 配置指定的集群。如果未指定可选查询参数 userid、流名称和流运行 ID,则将根据存储在底层存储实现中的流上下文信息,基于应用 ID 和集群 ID 进行查询。
GET /ws/v2/timeline/apps/{appid}/entity-types
or
GET /ws/v2/timeline/clusters/{clusterid}/apps/{appid}/entity-types
userid - 如果指定,则实体必须属于此用户。此查询参数必须与 flowname 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则时间线读取器将在执行查询时根据集群和 appid 获取流上下文信息。flowname - 如果指定,则实体必须属于此流名称。此查询参数必须与 userid 和 flowrunid 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们将不得不基于集群和 appid 获取流上下文信息。flowrunid - 如果指定,则实体必须属于此流运行 ID。此查询参数必须与 userid 和 flowname 查询参数一起指定,否则将被忽略。如果未指定 userid、flowname 和 flowrunid,则在执行查询时,我们将不得不基于集群和 appid 获取流上下文信息。{
YARN_APPLICATION_ATTEMPT,
YARN_CONTAINER,
MAPREDUCE_JOB,
MAPREDUCE_TASK,
MAPREDUCE_TASK_ATTEMPT
}
TimelineService v.2 支持提供历史应用的聚合日志。要启用此功能,请将 “yarn.log.server.web-service.url” 配置为 “${yarn .timeline-service.hostname}:8188/ws/v2/applicationlog” yarn-site.xml