
YARN 已知可以扩展到数千个节点。YARN 的可扩展性由资源管理器决定,并且与节点数、活动应用程序、活动容器以及心跳频率(节点和应用程序的)成正比。降低心跳可以提高可扩展性,但对利用率有害(请参见旧的 Hadoop 1.x 体验)。本文档描述了一种基于联合的方法,通过联合多个 YARN 子集群将单个 YARN 集群扩展到数万个节点。建议的方法是将一个大型(10-100k 节点)集群划分为称为子集群的较小单元,每个单元都有自己的 YARN RM 和计算节点。联合系统将把这些子集群拼接在一起,并使它们对应用程序显示为一个大型 YARN 集群。在此联合环境中运行的应用程序将看到一个单一的大型 YARN 集群,并且能够在联合集群的任何节点上调度任务。在底层,联合系统将与子集群资源管理器协商,并向应用程序提供资源。目标是允许单个作业无缝“跨越”子集群。
此设计在结构上是可扩展的,因为我们限制了每个 RM 负责的节点数量,并且适当的策略将尝试确保大多数应用程序将驻留在单个子集群中,因此每个 RM 将看到的应用程序数量也受到限制。这意味着我们可以通过简单地添加子集群(因为它们之间几乎不需要协调)来实现近乎线性的扩展。此架构可以在每个子集群内提供调度不变量的非常严格的执行(简单地继承自 YARN),而跨子集群的连续重新平衡将(不太严格地)强制这些属性在全局级别上也得到尊重(例如,如果子集群丢失大量节点,我们可以将队列重新映射到其他子集群,以确保在受损子集群上运行的用户不会受到不公平的影响)。
联合被设计为现有 YARN 代码库之上的“层”,对核心 YARN 机制进行了有限的更改。
假设
已知 OSS YARN 可以扩展到大约几千个节点。提议的架构利用了将许多这样的较小 YARN 集群(称为子集群)联合成一个包含数万个节点的更大联合 YARN 集群的概念。在此联合环境中运行的应用程序会看到一个统一的大型 YARN 集群,并且能够在集群中的任何节点上调度任务。在后台,联合系统将与子集群 RM 协商,并向应用程序提供资源。图 1 中的逻辑架构显示了构成联合集群的主要组件,如下所述。
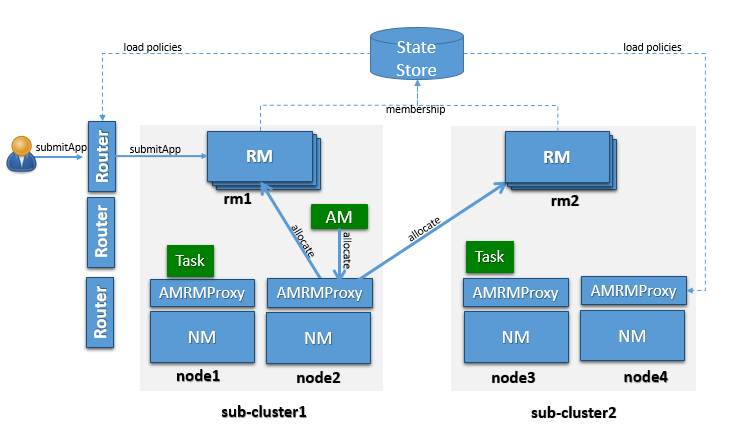
子集群是一个最多有几千个节点的 YARN 集群。子集群的确切大小将根据部署/维护的难易程度、与网络或可用性区域的对齐以及一般最佳实践来确定。
子集群 YARN RM 将在启用工作保留的高可用性情况下运行,即我们应该能够以最小的中断容忍 YARN RM、NM 故障。如果整个子集群受到损害,外部机制将确保在单独的子集群中重新提交作业(这最终可以包含在联合设计中)。
子集群也是联合环境中的可扩展性单元。我们可以通过添加一个或多个子集群来扩展联合环境。
注意:根据设计,每个子集群都是一个功能齐全的 YARN RM,它对联合的贡献可以设置为其整体容量的一部分,即子集群可以对联合做出“部分”承诺,同时保留以完全本地方式提供其部分容量的能力。
YARN 应用程序提交到其中一个路由器,该路由器进而应用路由策略(从策略存储中获取),查询状态存储以获取子群集 URL,并将应用程序提交请求重定向到适当的子群集 RM。我们将作业启动所在的子群集称为“主子群集”,并将作业跨越的所有其他子群集称为“辅助子群集”。路由器向外部世界公开 ApplicationClientProtocol,透明地隐藏了多个 RM 的存在。为了实现这一点,路由器还将应用程序与其主子群集之间的映射持久保存到状态存储中。这允许路由器在以低成本支持用户请求的同时保持软状态,因为任何路由器都可以恢复此应用程序到主子群集的映射,并将请求直接发送到正确的 RM,而无需广播它们。对于性能缓存和会话粘性而言,这可能是明智的。联合体(包括应用程序和节点)的状态通过 Web UI 公开。
AMRMProxy 是一个关键组件,允许应用程序跨子群集扩展和运行。AMRMProxy 在所有 NM 机器上运行,并通过实现 ApplicationMasterProtocol 充当 AM 的 YARN RM 代理。应用程序将不被允许直接与子群集 RM 通信。系统强制它们仅连接到 AMRMProxy 端点,该端点将提供对多个 YARN RM 的透明访问(通过动态路由/拆分/合并通信)。在任何时候,一个作业都可以跨越一个主子群集和多个辅助子群集,但 AMRMProxy 中运行的策略会尝试限制每个作业的占用空间,以最大程度地减少调度基础架构的开销(有关可扩展性/负载的更多信息,请参见该部分)。ARMMProxy 的拦截器链架构如图所示。
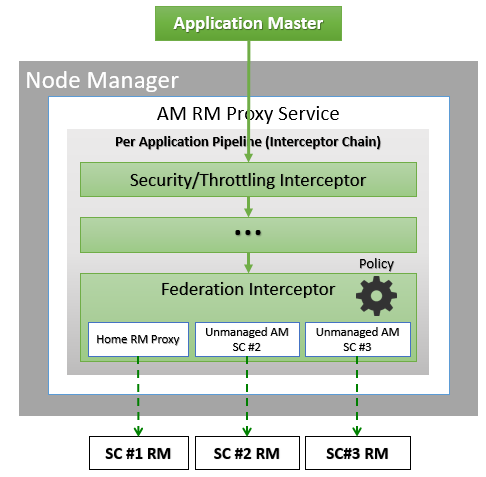
AMRMProxy 的作用
全局策略生成器将整个联合体纳入考虑范围,并确保系统始终配置得当且调整得当。一个关键设计点是集群可用性不依赖于始终开启的 GPG。GPG 持续运行,但与所有集群操作分离,并为我们提供一个独特的有利位置,可以强制实施全局不变性、影响负载平衡、触发将接受维护的子集群的排空等。更准确地说,GPG 将更新用户容量分配到子集群的映射,并且更少地更改路由器、AMRMProxy(以及可能的 RM)中运行的策略。
如果 GPG 不可用,集群操作将继续从 GPG 上次发布策略时开始,并且虽然长期不可用可能意味着某些理想的平衡属性、最佳集群利用率和全局不变性可能会消失,但计算和数据访问不会受到影响。
注意:在当前实现中,GPG 是一个手动调整过程,只需通过 CLI(YARN-3657)公开。
联合体系统中的这一部分是 YARN-5597 中未来工作的组成部分。
联合体状态定义了将多个独立子集群松散耦合到一个大型联合体集群中所需的附加状态。这包括以下信息
成员 YARN RM 持续向状态存储发送心跳以保持活动状态并发布其当前功能/负载信息。此信息由全局策略生成器 (GPG) 用于做出适当的策略决策。此外,路由器可以使用此信息选择最佳的主子集群。此机制允许我们通过添加或删除子集群来动态增加/缩减“集群机群”。这也允许轻松维护每个子集群。这是需要添加到 YARN RM 的新功能,但机制已得到充分理解,因为它类似于单个 YARN RM HA。
运行应用程序主控(AM)的子集群称为应用程序的“主子集群”。AM 不仅限于主子集群的资源,还可以请求其他子集群(称为辅助子集群)的资源。联合环境将定期配置和调整,以便在 AM 放置在子集群上时,它应该能够在主子集群上找到大部分资源。只有在某些情况下,它才需要请求其他子集群的资源。
联合策略存储是一个逻辑上独立的存储(尽管它可能由同一物理组件支持),其中包含有关如何将应用程序和资源请求路由到不同子集群的信息。当前实现提供了多种策略,从随机/哈希/循环/优先级到更复杂的策略,这些策略考虑了子集群负载和请求位置需求。
提交应用程序时,系统将确定运行应用程序的最合适的子集群,我们称之为应用程序的主子集群。AM 与 RM 之间的所有通信都将通过在 AM 机器上本地运行的 AMRMProxy 代理。AMRMProxy 公开了与 YARN RM 相同的 ApplicationMasterService 协议端点。AM 可以使用存储层公开的位置信息请求容器。在理想情况下,应用程序将被放置在应用程序所需的所有资源和数据都可用的子集群上,但如果确实需要其他子集群中节点上的容器,AMRMProxy 将与那些子集群的 RM 透明地协商并向应用程序提供资源,从而使应用程序能够将整个联合环境视为一个巨大的 YARN 集群。AMRMProxy、全局策略生成器 (GPG) 和路由器共同协作以无缝地实现这一点。
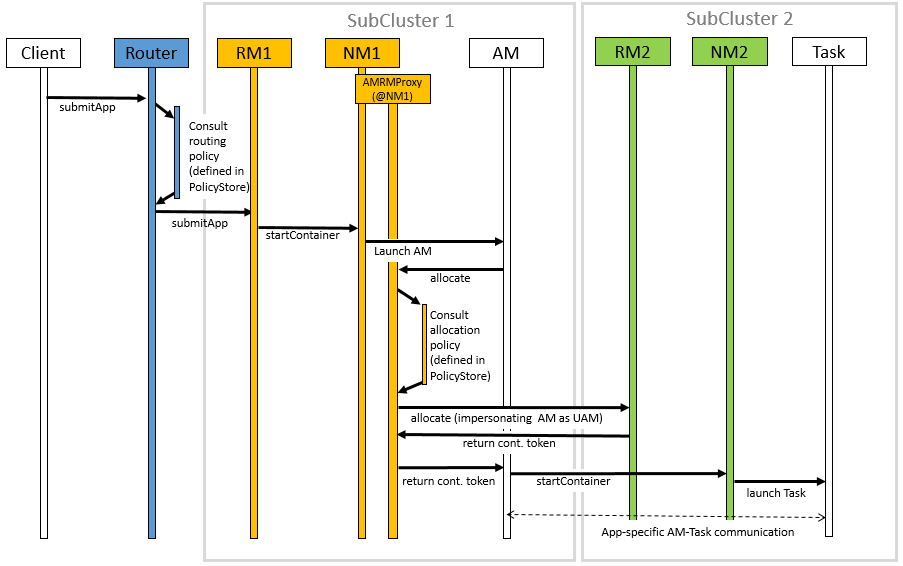
该图显示了以下作业执行流程的顺序图
若要将 YARN 配置为使用 Federation,请在 conf/yarn-site.xml 中设置以下属性
这些是通用配置,应出现在联合中的每台机器上的 conf/yarn-site.xml 中。
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.federation.enabled |
true |
联合是否启用 |
yarn.resourcemanager.cluster-id |
<unique-subcluster-id> |
此 RM 的唯一子集群标识符(与 HA 使用的标识符相同)。 |
目前,我们支持基于 ZooKeeper 和 SQL 的状态存储实现。
注意:状态存储实现必须始终用以下内容之一覆盖。
ZooKeeper:必须为 Hadoop 设置 ZooKeeper 设置
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.federation.state-store.class |
org.apache.hadoop.yarn.server.federation.store.impl.ZookeeperFederationStateStore |
要使用的状态存储类型。 |
hadoop.zk.address |
host:port |
ZooKeeper 集群的地址。 |
SQL:必须设置以下参数
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.federation.state-store.class |
org.apache.hadoop.yarn.server.federation.store.impl.SQLFederationStateStore |
要使用的状态存储类型。 |
yarn.federation.state-store.sql.url |
jdbc:mysql://<host>:<port>/FederationStateStore |
对于 SQLFederationStateStore,存储状态的数据库名称。 |
yarn.federation.state-store.sql.jdbc-class |
com.mysql.jdbc.jdbc2.optional.MysqlDataSource |
对于 SQLFederationStateStore,要使用的 jdbc 类。 |
yarn.federation.state-store.sql.username |
<dbuser> |
对于 SQLFederationStateStore,数据库连接的用户名。 |
yarn.federation.state-store.sql.password |
<dbpass> |
对于 SQLFederationStateStore,数据库连接的密码。 |
我们提供了适用于 MySQL 和 Microsoft SQL Server 的脚本。
对于 MySQL,必须从 MVN Repository 下载最新 jar 版本 5.x 并将其添加到 CLASSPATH。然后,通过在数据库中执行以下 SQL 脚本来创建数据库架构
在同一目录中,我们提供了删除存储过程、表、用户和数据库的脚本。
注意:FederationStateStoreUser.sql 为数据库定义了一个默认用户/密码,强烈建议您将其设置为适当的强密码。
对于 SQL-Server,该过程类似,但已包含 jdbc 驱动程序。SQL-Server 脚本位于 sbin/FederationStateStore/SQLServer/ 中。
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.federation.failover.enabled |
true |
是否应在每个子集群内考虑 RM 故障转移重试。 |
yarn.federation.blacklist-subclusters |
<subcluster-id> |
黑名单子集群列表,可用于禁用子集群 |
yarn.federation.policy-manager |
org.apache.hadoop.yarn.server.federation.policies.manager.WeightedLocalityPolicyManager |
策略管理器选择决定应用程序和资源请求如何通过系统路由。 |
yarn.federation.policy-manager-params |
<binary> |
配置策略的有效负载。在我们的示例中,为路由器和 amrmproxy 策略设置了一组权重。这通常通过序列化已通过编程配置的策略管理器或通过使用其 .json 序列化形式填充状态存储来生成。 |
yarn.federation.subcluster-resolver.class |
org.apache.hadoop.yarn.server.federation.resolver.DefaultSubClusterResolverImpl |
用于解析节点所属子集群以及机架所属子集群的类。 |
yarn.federation.machine-list |
<机器列表文件路径> |
SubClusterResolver 使用的机器列表文件路径。该文件中的每一行都是一个具有子集群和机架信息的节点。以下是示例node1, subcluster1, rack1 node2, subcluster2, rack1 node3, subcluster3, rack2 node4, subcluster3, rack2 |
这些是应出现在每个 ResourceManager 中的 conf/yarn-site.xml 中的额外配置。
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.resourcemanager.epoch |
<unique-epoch> |
纪元的种子值。这用于保证由不同 RM 生成的容器 ID 的唯一性。因此,它在子集群中必须是唯一的,并且间隔良好以允许导致纪元递增的故障。1000 的增量允许大量子集群,并且实际上确保几乎没有冲突的可能性(只有当一个容器在其中一个 RM 的 1000 次重新启动中仍然存活,而下一个 RM 从未重新启动,并且应用程序请求更多容器时,才会发生冲突)。 |
可选
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.federation.state-store.heartbeat-interval-secs |
60 |
RM 向中央状态存储报告其成员资格到联盟的速率。 |
这些是应出现在每个路由器中的 conf/yarn-site.xml 中的额外配置。
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.router.bind-host |
0.0.0.0 |
绑定路由器的主机 IP。服务器将绑定的实际地址。如果设置此可选地址,RPC 和 Webapp 服务器将分别绑定到此地址和 yarn.router.*.address 中指定的端口。这对于通过将地址设置为 0.0.0.0 使路由器侦听所有接口非常有用。 |
yarn.router.clientrm.interceptor-class.pipeline |
org.apache.hadoop.yarn.server.router.clientrm.FederationClientInterceptor |
与客户端交互时在路由器上运行的拦截器类的逗号分隔列表。此管道中的最后一步必须是联合客户端拦截器。 |
可选
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.router.hostname |
0.0.0.0 |
路由器主机名。 |
yarn.router.clientrm.address |
0.0.0.0:8050 |
路由器客户端地址。 |
yarn.router.webapp.address |
0.0.0.0:8089 |
路由器上的 Webapp 地址。 |
yarn.router.admin.address |
0.0.0.0:8052 |
路由器上的管理地址。 |
yarn.router.webapp.https.address |
0.0.0.0:8091 |
路由器上的安全 Webapp 地址。 |
yarn.router.submit.retry |
3 |
在放弃之前,路由器中的重试次数。 |
yarn.federation.statestore.max-connections |
10 |
这是每个路由器与状态存储建立的最大并行连接数。 |
yarn.federation.cache-ttl.secs |
60 |
路由器缓存信息,这是在缓存失效之前保留的时间。 |
yarn.router.webapp.interceptor-class.pipeline |
org.apache.hadoop.yarn.server.router.webapp.FederationInterceptorREST |
通过 REST 接口与客户端交互时在路由器上运行的拦截器类的逗号分隔列表。此管道中的最后一步必须是联合拦截器 REST。 |
这些是应出现在每个 NodeManager 中的 conf/yarn-site.xml 中的额外配置。
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.nodemanager.amrmproxy.enabled |
true |
AMRMProxy 是否启用。 |
yarn.nodemanager.amrmproxy.interceptor-class.pipeline |
org.apache.hadoop.yarn.server.nodemanager.amrmproxy.FederationInterceptor |
在 amrmproxy 上运行的拦截器的逗号分隔列表。对于联合,管道中的最后一步应该是 FederationInterceptor。 |
可选
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.nodemanager.amrmproxy.ha.enable |
true |
AMRMProxy HA 是否启用以支持多个应用程序尝试。 |
yarn.federation.statestore.max-connections |
1 |
每个 AMRMProxy 与状态存储之间并行连接的最大数量。此值通常低于路由器值,因为我们有许多 AMRMProxy 可能很快就会耗尽许多数据库连接。 |
yarn.federation.cache-ttl.secs |
300 |
AMRMProxy 缓存的保留时间。通常大于路由器,因为 AMRMProxy 的数量很大,并且我们希望限制对集中式状态存储的负载。 |
为了向联合集群提交作业,必须为作业提交方创建一组单独的配置。在这些配置中,conf/yarn-site.xml 应具有以下附加配置
| 属性 | 示例 | 说明 |
|---|---|---|
yarn.resourcemanager.address |
<router_host>:8050 |
将客户端启动的作业重定向到路由器的客户端 RM 端口。 |
yarn.resourcemanager.scheduler.address |
localhost:8049 |
将作业重定向到联合 AMRMProxy 端口。 |
可以从上面描述的客户端配置提交集群的任何 YARN 作业。为了通过联合启动作业,首先启动联合中涉及的所有集群,如此处所述。接下来,使用以下命令在路由器机器上启动路由器
$HADOOP_HOME/bin/yarn --daemon start router
现在,将 $HADOOP_CONF_DIR 指向上面描述的客户端配置文件夹,以通常的方式运行作业。上面描述的客户端配置文件夹中的配置会将作业定向到路由器的客户端 RM 端口,路由器在启动后应侦听该端口。以下是客户端在联合集群上运行 Pi 作业的示例
$HADOOP_HOME/bin/yarn jar hadoop-mapreduce-examples-3.0.0.jar pi 16 1000
此作业提交到路由器,如上所述,路由器使用从GPG生成的策略为作业选择一个主 RM,作业提交到该主 RM。
此特定示例作业的输出应如下所示
2017-07-13 16:29:25,055 INFO mapreduce.Job: Job job_1499988226739_0001 running in uber mode : false 2017-07-13 16:29:25,056 INFO mapreduce.Job: map 0% reduce 0% 2017-07-13 16:29:33,131 INFO mapreduce.Job: map 38% reduce 0% 2017-07-13 16:29:39,176 INFO mapreduce.Job: map 75% reduce 0% 2017-07-13 16:29:45,217 INFO mapreduce.Job: map 94% reduce 0% 2017-07-13 16:29:46,228 INFO mapreduce.Job: map 100% reduce 100% 2017-07-13 16:29:46,235 INFO mapreduce.Job: Job job_1499988226739_0001 completed successfully . . . Job Finished in 30.586 seconds Estimated value of Pi is 3.14250000......
还可以在 routerhost:8089 上的路由器 Web UI 中跟踪作业状态。请注意,使用联合无需更改代码或重新编译输入 jar。此外,此作业的输出与在没有联合的情况下运行时的输出完全相同。此外,为了充分利用联合,请使用足够多的映射器,以便需要多个集群。在上述示例中,该数字恰好为 16。