
NameNode 具有可扩展性限制,原因在于元数据开销由 inode(文件和目录)和文件块、DataNode 心跳数以及 HDFS RPC 客户端请求数组成。常见的解决方案是将文件系统拆分为较小的子集群 HDFS 联合,并提供联合视图 ViewFs。问题在于如何维护子集群的拆分(例如,名称空间分区),这迫使用户连接到多个子集群并管理向它们分配文件夹/文件。
对这种分区联合的自然扩展是添加一个负责联合命名空间的软件层。这个额外的层允许用户透明地访问任何子集群,让子集群独立管理自己的块池,并且以后将支持跨子集群重新平衡数据(更多信息请参阅 HDFS-13123)。RBF 中的子集群不必是独立的 HDFS 集群,普通的联合集群(具有多个块池)或具有联合和独立集群的混合集群也是允许的。为了实现这些目标,联合层将块访问定向到正确的子集群,维护命名空间的状态,并提供数据重新平衡的机制。此层必须具有可扩展性、高可用性和容错性。
此联合层包含多个组件。路由器组件具有与 NameNode 相同的接口,并根据状态存储中的真实信息将客户端请求转发到正确的子集群。状态存储将远程装载表(采用 ViewFs 的形式,但在客户端之间共享)与有关子集群的利用率(负载/容量)信息结合起来。此方法具有与 YARN 联合 相同的架构。
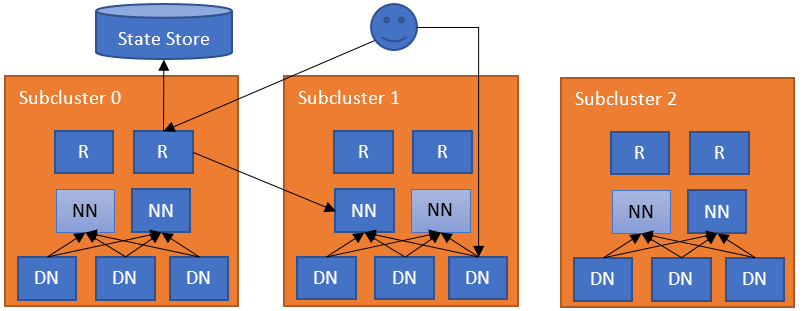
最简单的配置是在每个 NameNode 机器上部署一个路由器。路由器监视本地 NameNode 及其状态,并向状态存储发送心跳。路由器监视本地 NameNode,并将状态心跳到状态存储。当常规 DFS 客户端联系任何路由器以访问联合文件系统中的文件时,路由器会检查状态存储中的装载表(即本地缓存)以找出哪个子集群包含该文件。然后,它检查状态存储中的成员表(即本地缓存)以查找负责该子集群的 NameNode。在识别出正确的 NameNode 后,路由器会代理该请求。客户端直接访问数据节点。
系统中可以有多个具有软状态的路由器。每个路由器有两个角色
路由器接收客户端请求,检查状态存储以查找正确的子集群,并将请求转发到该子集群的活动 NameNode。然后,NameNode 的答复将按相反的方向流动。路由器是无状态的,可以位于负载均衡器之后。对于运行状况检查,可以使用 /isActive 端点作为运行状况探测(例如 http://ROUTER_HOSTNAME:ROUTER_PORT/isActive)。为了提高性能,路由器还会缓存远程装载表条目和子集群的状态。为了确保已将更改传播到所有路由器,每个路由器都会将其状态心跳到状态存储。
路由器和状态存储之间的通信被缓存(带有定时过期以保持新鲜度)。这提高了系统的性能。
路由器定期向状态存储发送其状态心跳。
对于此角色,路由器会定期检查 NameNode(通常在同一服务器上)的状态,并将它们的高可用性 (HA) 状态和负载/空间状态报告给状态存储。请注意,这是一个可选角色,因为路由器可以独立于任何子集群。为了提高 NameNode HA 的性能,路由器使用状态存储中的高可用性状态信息将请求转发到最有可能处于活动状态的 NameNode。请注意,此服务可以嵌入到 NameNode 本身中以简化操作。
路由器在多个级别上处理故障。
联合界面 HA:路由器是无状态的,元数据操作在 NameNode 中是原子的。如果路由器不可用,任何路由器都可以接管它。客户端使用联合中的所有路由器作为端点配置其 DFS HA 客户端(例如,ConfiguredFailoverProvider 或 RequestHedgingProxyProvider)。
不可用的状态存储:如果路由器无法连接到状态存储,它将进入安全模式状态,该状态不允许它处理请求。客户端将安全模式中的路由器视为备用 NameNode,并尝试其他路由器。有一种手动方法来管理路由器的安全模式。
可以使用以下命令管理安全模式状态
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -safemode enter | leave | get
NameNode 心跳 HA:为了实现高可用性和灵活性,多个路由器可以监视同一个 NameNode,并将信息发送到状态存储。如果路由器发生故障,这会提高客户端对陈旧信息的弹性。状态存储中冲突的 NameNode 信息由每个路由器通过法定人数解决。
不可用的 NameNode:如果路由器无法连接到活动 NameNode,则它将尝试子集群中的其他 NameNode。它将首先尝试那些报告为备用的 NameNode,然后尝试那些不可用的 NameNode。如果路由器无法连接到任何 NameNode,则会引发异常。
过期的 NameNode:如果 NameNode 心跳在状态存储中没有记录为心跳间隔的倍数,则监视路由器将记录 NameNode 已过期,并且没有路由器会尝试访问它。如果随后为 NameNode 记录了更新的心跳,则监视路由器将从过期状态恢复 NameNode。
为了与用户和管理员交互,路由器公开了多个接口。
RPC:路由器 RPC 实施了客户端用于与 HDFS 交互的最常见接口。当前实施已使用以纯 MapReduce、Spark 和 Hive(在 Tez、Spark 和 MapReduce 上)编写的分析工作负载进行了测试。快照、加密和分层存储等高级功能留待未来版本。所有未实施的功能都将引发异常。
管理员:管理员可以通过 RPC 查询集群信息,并从挂载表中添加/删除条目。此接口还通过命令行公开,以获取和修改联合的信息。
Web UI:路由器公开了一个 Web UI,可视化联合的状态,模仿当前的 NameNode UI。它显示有关挂载表、每个子集群的成员资格信息以及路由器状态的信息。
WebHDFS:路由器除了 RPC 接口外,还提供 HDFS REST 接口 (WebHDFS)。
JMX:它通过模仿 NameNode 公开指标。Web UI 使用此功能来获取集群状态。
在基于路由器的联合中,某些操作不可用。路由器会为此类操作引发异常。用户可能遇到的示例包括以下内容。
联合在挂载表级别支持和控制全局配额。出于性能原因,路由器会缓存配额使用情况并定期更新。这些配额使用情况值将在 RouterRPCSever 中调用的每次 WRITE RPC 调用期间用于配额验证。有关配额详细信息,请参阅HDFS 配额指南。
注意:启用全局配额时,不建议直接设置或清除子集群的配额,因为路由器管理员服务器将使用全局配额覆盖子集群的配额。
(逻辑上集中,但物理上分布的)状态存储维护
状态存储的后端是可插拔的。我们利用后端实施的容错性。状态存储中存储的主要信息及其实施
成员资格:成员资格信息对联合中的 NameNode 状态进行编码。这包括有关子集群的信息,例如存储容量和节点数。路由器定期对一个或多个 NameNode 的此信息进行心跳检测。鉴于多个路由器可以监视单个 NameNode,因此会存储来自每个路由器的心跳。路由器在从状态存储中查询此信息时应用数据的法定人数。路由器会丢弃超过特定阈值(例如,十个路由器心跳周期)的条目。
挂载表:此表承载文件夹和子集群之间的映射。它类似于 ViewFs 中的挂载表,其中指定了联合文件夹、目标子集群和该文件夹中的路径。
路由器支持类似于 HDFS 中的 当前安全模型 的安全性。此功能对 RPC 和基于 Web 的调用均可用。它能够代理到底层安全 HDFS 集群。
与 NameNode 类似,对于连接到路由器的客户端,支持基于 Kerberos 和令牌的身份验证。路由器在内部依赖于 core-site.xml 和 hdfs-site.xml 的现有安全相关配置来支持此功能。除此之外,还需要使用路由器自己的密钥表和主体来配置路由器。
对于基于令牌的身份验证,路由器向不与下游名称节点通信的上游客户端颁发委派令牌。路由器使用其自己的凭据安全地代理到下游名称节点,代表上游真实用户。路由器主体必须在所有安全的下游名称节点中配置为超级用户。请参阅 此处 以配置名称节点的代理用户。除此之外,拥有路由器守护程序的用户应配置为与名称节点进程本身相同的身份。有关详细信息,请参阅 此处。路由器依赖于状态存储来跨所有路由器分发令牌。除了提供给用户的默认实现之外,用户还可以插入自己的状态存储实现来进行令牌管理。默认实现依赖于 Zookeeper 进行令牌管理。由于大型路由器/Zookeeper 集群可能持有数百万个令牌,因此 Zookeeper 客户端依赖的 jute.maxbuffer 系统属性应在路由器守护程序中进行适当配置。
有关此功能的更多信息,请参见 Apache JIRA 工单 HDFS-13532。
默认情况下,路由器已准备好接收请求并监视本地计算机中的 NameNode。它需要通过设置 dfs.federation.router.store.driver.class 来了解状态存储端点。其余选项记录在 hdfs-rbf-default.xml 中。
配置路由器后,即可启动路由器
[hdfs]$ $HADOOP_PREFIX/bin/hdfs --daemon start dfsrouter
并停止路由器
[hdfs]$ $HADOOP_PREFIX/bin/hdfs --daemon stop dfsrouter
挂载表项与 ViewFs 中的项非常相似。简化管理的一个好方法是使用与目标命名空间相同的名称命名联合命名空间。例如,如果我们要在联合命名空间中挂载 /data/app1,建议在目标命名空间中使用相同的名称。
联合管理工具支持管理挂载表。例如,要创建三个挂载点并列出这些挂载点
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /tmp ns1 /tmp [hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /data/app1 ns2 /data/app1 [hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /data/app2 ns3 /data/app2 [hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -ls
它还支持禁止写入的挂载点
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /readonly ns1 / -readonly
如果未设置挂载点,路由器会将其映射到默认命名空间 dfs.federation.router.default.nameserviceId。
挂载表具有类似 UNIX 的权限,用于限制哪些用户和组可以访问挂载点。写入权限允许用户添加、更新或删除挂载点。读取权限允许用户列出挂载点。执行权限未使用。
可以通过以下命令设置挂载表权限
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /tmp ns1 /tmp -owner root -group supergroup -mode 0755
选项模式是挂载表的 UNIX 风格权限。权限以八进制形式指定,例如 0755。默认情况下,此项设置为 0755。
基于路由器的联合支持挂载表级别的全局配额。挂载表项可能会跨多个子群集,并且会在这些子群集之间计算全局配额。
联合管理工具支持为指定的挂载表项设置配额
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -setQuota /path -nsQuota 100 -ssQuota 1024
上述命令表示我们允许路径最多有 100 个文件/目录,并且最多使用 1024 字节的存储空间。ssQuota 参数支持多个大小单位后缀(例如 1k 为 1KB,5m 为 5MB)。如果未指定后缀,则假定为字节。
为指定的挂载表项设置存储类型配额
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -setStorageTypeQuota <path> -storageType <storage type>
删除指定挂载表项的配额
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -clrQuota <path>
删除指定挂载表项的存储类型配额
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -clrStorageTypeQuota <path>
Ls 命令会为每个挂载表项显示以下信息
Source Destinations Owner Group Mode Quota/Usage /path ns0->/path root supergroup rwxr-xr-x [NsQuota: 50/0, SsQuota: 100 B/0 B]
挂载表缓存会定期刷新,但也可以通过执行刷新命令来刷新缓存
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -refresh
上述命令会刷新已连接路由器的缓存。当启用挂载表刷新服务时,此命令是多余的,因为该服务会始终保持缓存更新。
挂载点还支持映射多个子群集。例如,要创建一个将文件存储在子群集 ns1 和 ns2 中的挂载点。
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /data ns1,ns2 /data -order SPACE
列出 /data 时,它会显示两个子群集中的所有文件夹和文件。它使用 order 参数来决定在何处创建新文件/文件夹,目前支持以下方法
对于基于哈希的方法,区别在于 HASH 会使文件夹中的所有文件/文件夹属于同一子集群,而 HASH_ALL 会将所有文件分布在挂载点下。例如,假设我们有一个用于 /data/hash 的 HASH 挂载点,则 /data/hash/folder0 下的文件和文件夹都将位于同一子集群中。另一方面,用于 /data/hash_all 的 HASH_ALL 挂载点会将 /data/hash_all/folder0 下的文件分布在该挂载点的所有子集群中(子文件夹将创建到所有子集群)。
RANDOM 可用于从/向不同的子集群读取和写入数据。此方法的常见用途是在多个子集群中拥有相同的数据,并在子集群之间平衡读取。例如,如果数千个容器需要读取相同的数据(例如,一个库),则可以使用 RANDOM 从任何子集群读取数据。
确定哪个子集群包含文件
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -getDestination /user/user1/file.txt
请注意,路由器不保证子集群之间的数据一致性。默认情况下,如果一个子集群不可用,则写入可能会失败,如果它们以该子集群为目标。要允许在另一个子集群中写入,可以使挂载点具有容错能力
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -add /data ns1,ns2 /data -order HASH_ALL -faulttolerant
请注意,这可能导致文件写入多个子集群或一个文件夹在一个子集群中丢失。需要意识到这些不一致的可能性,并将此 faulttolerant 方法定位到弹性路径。一个示例是 /app-logs 文件夹,它主要一次写入一个子文件夹。
为了防止访问名称服务(子集群),可以从联合中禁用它。例如,可以禁用 ns1,列出它并再次启用它
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -nameservice disable ns1 [hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -getDisabledNameservices [hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -nameservice enable ns1
这在退役子集群或一个子集群行为不当时(例如,性能低下或不可用)很有用。
触发 <host:ipc_port> 上 <key> 指定的资源的运行时刷新。例如,要启用白名单检查,我们只需要发送刷新命令,而不是重新启动路由器服务器。
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -refreshRouterArgs <host:ipc_port> <key> [arg1..argn]
要诊断路由器的当前状态,可以使用 dumpState 命令。它生成状态存储中记录的文本转储。由于它使用配置来查找和读取状态存储,因此通常最简单的方法是在路由器运行的机器上使用它。该命令在本地运行,因此路由器不必启动即可使用此命令。
[hdfs]$ $HADOOP_HOME/bin/hdfs dfsrouteradmin -dumpState
要让客户端使用联合命名空间,他们需要创建一个指向路由器的新命名空间。例如,一个有 4 个命名空间 ns0、ns1、ns2、ns3 的集群,可以在 hdfs-site.xml 中添加一个新的命名空间,称为 ns-fed,它指向两个路由器
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns0,ns1,ns2,ns3,ns-fed</value>
</property>
<property>
<name>dfs.ha.namenodes.ns-fed</name>
<value>r1,r2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns-fed.r1</name>
<value>router1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns-fed.r2</name>
<value>router2:rpc-port</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns-fed</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.client.failover.random.order</name>
<value>true</value>
</property>
</configuration>
将 dfs.client.failover.random.order 设置为 true 允许在路由器之间均匀分配负载。
通过此设置,用户可以将 ns-fed 作为常规命名空间进行交互
$ $HADOOP_HOME/bin/hdfs dfs -ls hdfs://ns-fed/ /tmp /data
此联合命名空间也可以使用 fs.defaultFS 在 core-site.xml 中设置为默认命名空间。
为了让系统支持数据局部性,您必须配置您的 NameNode,以便它们信任路由器来提供用户的客户端 IP 地址。dfs.namenode.ip-proxy-users 定义了一个逗号分隔的用户列表,这些用户允许通过调用者上下文提供客户端 IP 地址。
<configuration>
<property>
<name>dfs.namenode.ip-proxy-users</name>
<value>hdfs</value>
</property>
</configuration>
可以在 hdfs-rbf-site.xml 中添加基于路由器的联合的配置。主要选项在 hdfs-rbf-default.xml 中记录。配置值在此部分中描述。
从客户端接收连接的 RPC 服务器。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.default.nameserviceId | 要监视的默认子群集的名称服务标识符。 | |
| dfs.federation.router.rpc.enable | true |
如果为 true,则启用路由器中处理客户端请求的 RPC 服务。 |
| dfs.federation.router.rpc-address | 0.0.0.0:8888 | 处理所有客户端请求的 RPC 地址。 |
| dfs.federation.router.rpc-bind-host | 0.0.0.0 | RPC 服务器将绑定的实际地址。 |
| dfs.federation.router.handler.count | 10 | 路由器处理来自客户端的 RPC 请求的服务器线程数。 |
| dfs.federation.router.handler.queue.size | 100 | 处理 RPC 客户端请求的处理程序数量的队列大小。 |
| dfs.federation.router.reader.count | 1 | 路由器处理 RPC 客户端请求的读取器数量。 |
| dfs.federation.router.reader.queue.size | 100 | 路由器处理 RPC 客户端请求的读者数量队列大小。 |
路由器将客户端请求转发给 NameNode。它使用连接池来减少创建连接的延迟。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.connection.pool-size | 1 | 从路由器到 NameNode 的连接池大小。 |
| dfs.federation.router.connection.clean.ms | 10000 | 以毫秒为单位的时间间隔,用于检查连接池是否应移除未使用的连接。 |
| dfs.federation.router.connection.pool.clean.ms | 60000 | 以毫秒为单位的时间间隔,用于检查连接管理器是否应移除未使用的连接池。 |
管理装载表管理服务器。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.admin.enable | true |
如果为 true,则启用 RPC 管理服务来处理路由器中的客户端请求。 |
| dfs.federation.router.admin-address | 0.0.0.0:8111 | 处理管理请求的 RPC 地址。 |
| dfs.federation.router.admin-bind-host | 0.0.0.0 | RPC 管理服务器将绑定的实际地址。 |
| dfs.federation.router.admin.handler.count | 1 | 路由器处理来自管理的 RPC 请求的服务器线程数量。 |
HTTP 服务器为客户端提供 Web UI 和 HDFS REST 接口 (WebHDFS)。默认 URL 为“http://router_host:50071”。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.http.enable | true |
如果为 true,则启用 HTTP 服务来处理路由器中的客户端请求。 |
| dfs.federation.router.http-address | 0.0.0.0:50071 | 处理对路由器的 Web 请求的 HTTP 地址。 |
| dfs.federation.router.http-bind-host | 0.0.0.0 | HTTP 服务器将绑定的实际地址。 |
| dfs.federation.router.https-address | 0.0.0.0:50072 | 处理对路由器的 Web 请求的 HTTPS 地址。 |
| dfs.federation.router.https-bind-host | 0.0.0.0 | HTTPS 服务器将绑定的实际地址。 |
与状态存储的连接以及路由器中的内部缓存。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.store.enable | true |
如果为 true,则路由器连接到状态存储。 |
| dfs.federation.router.store.serializer | org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreSerializerPBImpl |
序列化状态存储记录的类。 |
| dfs.federation.router.store.driver.class | org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreZooKeeperImpl |
实现状态存储的类。 |
| dfs.federation.router.store.connection.test | 60000 | 以毫秒为单位,检查与状态存储的连接的频率。 |
| dfs.federation.router.cache.ttl | 60000 | 以毫秒为单位,刷新状态存储缓存的频率。 |
| dfs.federation.router.store.membership.expiration | 300000 | 成员记录的过期时间(以毫秒为单位)。 |
| dfs.federation.router.mount-table.cache.update | false | 如果为 true,则每当为所有路由器添加、修改或删除装入表项时,都会更新装入表缓存。 |
| dfs.federation.router.mount-table.cache.update.timeout | 1m | 等待所有路由器完成其装入表缓存更新的最大时间。 |
| dfs.federation.router.mount-table.cache.update.client.max.time | 5m | RouterClient 连接可被缓存的最大时间。 |
将客户端请求转发到正确的子群集。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.file.resolver.client.class | org.apache.hadoop.hdfs.server.federation.resolver.MountTableResolver |
用于将文件解析到子群集的类。要为装入点启用多个子群集,请将其设置为 org.apache.hadoop.hdfs.server.federation.resolver.MultipleDestinationMountTableResolver。 |
| dfs.federation.router.namenode.resolver.client.class | org.apache.hadoop.hdfs.server.federation.resolver.MembershipNamenodeResolver |
用于解析子群集的名称节点的类。 |
监视子群集中的名称节点,以转发客户端请求。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.heartbeat.enable | true |
如果为 true,则路由器会定期将其状态心跳到状态存储。 |
| dfs.federation.router.namenode.heartbeat.enable | 如果为 true,则路由器获取名称节点心跳并发送到状态存储。如果没有明确指定,则采用与 dfs.federation.router.heartbeat.enable 相同的值。 | |
| dfs.federation.router.heartbeat.interval | 5000 | 路由器应以毫秒为单位向状态存储心跳的频率。 |
| dfs.federation.router.monitor.namenode | 要监视和心跳的名称节点的标识符。 | |
| dfs.federation.router.monitor.localnamenode.enable | true |
如果为 true,则路由器应监视本地计算机中的名称节点。 |
注意:如果启用了 dfs.federation.router.monitor.localnamenode.enable,则建议配置 dfs.nameservice.id。这将允许路由器直接找到本地节点。否则,它将通过将名称节点 RPC 地址与本地节点地址进行匹配来找到名称服务 ID。如果匹配多个地址,路由器将无法启动。此外,如果本地节点处于 HA 模式,则建议配置 dfs.ha.namenode.id。
联合中支持的全局配额。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.quota.enable | false |
如果为 true,则在路由器中启用配额系统。在这种情况下,不建议直接设置或清除子群集的配额,因为路由器管理服务器将用全局配额覆盖子群集的配额。 |
| dfs.federation.router.quota-cache.update.interval | 60s | 路由器更新配额缓存的频率。此设置支持多个时间单位后缀。如果没有指定后缀,则假定为毫秒。 |
联合中支持 Kerberos 和委派令牌。
| 属性 | 默认值 | 说明 |
|---|---|---|
| dfs.federation.router.keytab.file | 路由器用作其服务主体登录时使用的密钥表文件。主体名称配置为“dfs.federation.router.kerberos.principal”。 | |
| dfs.federation.router.kerberos.principal | 路由器服务主体。通常设置为 router/_HOST@REALM.TLD。每个路由器在启动时都会用自己的完全限定主机名替换 _HOST。_HOST 占位符允许在 HA 设置中的所有路由器上使用相同的配置设置。 | |
| dfs.federation.router.kerberos.principal.hostname | 包含此配置文件的路由器的主机名。对于每台机器来说都不同。默认为当前主机名。 | |
| dfs.federation.router.kerberos.internal.spnego.principal | ${dfs.web.authentication.kerberos.principal} |
启用 Kerberos 安全性时,路由器用于 Web UI SPNEGO 身份验证的服务器主体。通常设置为 HTTP/_HOST@REALM.TLD。根据惯例,SPNEGO 服务器主体以前缀 HTTP/ 开头。如果值为“*”,Web 服务器将尝试使用密钥表文件“dfs.web.authentication.kerberos.keytab”中指定的每个主体登录。 |
| dfs.federation.router.secret.manager.class | org.apache.hadoop.hdfs.server.federation.router.security.token.ZKDelegationTokenSecretManagerImpl |
用于实现委派令牌状态存储的类。默认实现使用 Zookeeper 作为存储委派令牌的后端。 |
路由器和状态存储统计信息在指标/JMX 中公开。这些信息对于监控非常有用。更多指标信息,请参见 RBF 指标、路由器 RPC 指标 和 状态存储指标。